L06 MDP in Finance
DO NOT DISTRIBUTE.
- L06 MDP in Finance
- MDP Theory
- The Financial Markets
- MDP Applications in Finance
MDP Theory
Introduction
Introduction
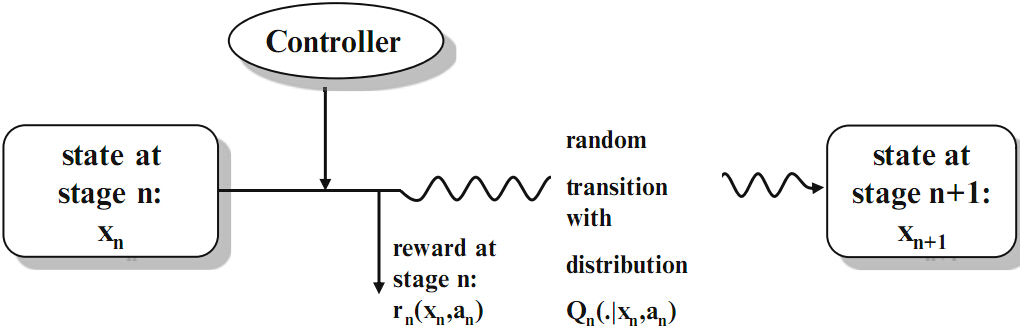
The Markov Decision Process is the sequence of random variables () which describes the stochastic evolution
of the system states. Of course the distribution of () depends on the chosen actions.
-
denotes the state space of the system. A state is the information which is available for the controller at time . Given this information an action has to be selected.
-
denotes the action space. Given a specific state at time , a certain subclass of actions may only be admissible.
-
is a stochastic transition kernel which gives the probability that the next state at time is in the set B if the current state is and action a is taken at time .
-
gives the (discounted) one-stage reward of the system at time if the current state is and action a is taken
-
gives the (discounted) terminal reward of the system at the end of the planning horizon.
A control is a sequence of decision rules () with where determines for each possible state the next action at time . Such a sequence is called policy or strategy. Formally the Markov Decision Problem is given by
-
Types of MDP problems:
- finite horizon () vs. infinite horizon ()
- complete state observation vs. partial state observation
- problems with constraints vs. without constraints
- total (discounted) cost criterion vs. average cost criterion
-
Research questions:
- Does an optimal policy exist?
- Has it a particular form?
- Can an optimal policy be computed efficiently?
- Is it possible to derive properties of the optimal value function analytically?
Applications: Consumption Problem
-
Consumption Problem
Suppose there is an investor with given initial capital. At the beginning of each of periods she can decide how much of the capital she consumes and how much she invests into a risky asset. The amount she consumes is evaluated by a utility function as well as the terminal wealth. The remaining capital is invested into a risky asset where we assume that the investor is small and thus not able to influence the asset price and the asset is liquid. How should she consume/invest in order to maximize the sum of her expected discounted utility? -
Cash Balance or Inventory Problem
Imagine a company which tries to find the optimal level of cash over a finite number of periods. We assume that there is a random stochastic change in the cash reserve each period (due to withdrawal or earnings). Since the firm does not earn interest from the cash position, there are holding cost for the cash reserve if it is positive, but also interest (cost) in case it is negative. The cash reserve can be increased or decreased by the management at each decision epoch which implies transfer costs. What is the optimal cash balance policy? -
Mean-Variance Problem
Consider a small investor who acts on a given financial market. Her aim is to choose among all portfolios which yield at least a certain expected return (benchmark) after periods, the one with smallest portfolio variance. What is the optimal investment strategy? -
Dividend Problem in Risk Theory
Imagine we consider the risk reserve of an insurance company which earns some premia on the one hand but has to pay out possible claims on the other hand. At the beginning of each period the insurer can decide upon paying a dividend. A dividend can only be paid when the risk reserve at that time point is positive. Once the risk reserve got negative we say that the company is ruined and has to stop its business. Which dividend pay-out policy maximizes the expected discounted dividends until ruin? -
Bandit Problem
Suppose we have two slot machines with unknown success probability and . At each stage we have to choose one of the arms. We receive one Euro if the arm wins, else no cash flow appears. How should we play in order to maximize our expected total reward over trials? -
Pricing of American Options
In order to find the fair price of an American option and its optimal exercise time, one has to solve an optimal stopping problem. In contrast to a European option the buyer of an American option can choose to exercise any time up to and including the expiration time. Such an optimal stopping problem can be solved in the framework of Markov Decision Processes.
A Reference Book

You may buy it via Amazon, or find it via Springer Link
Markov Decision Models
Defining A Markov Decision Models
Markov Decision Model with planning horizon consists of a set of data with the following meaning for :
-
is the state space, endowed with a -algebra . The elements (states) are denoted by
-
is the action space, endowed with a -algebra . The elements (actions) are denoted by
-
is a measurable subset of and denotes the set of possible state-action combinations at time . We assume that contains the graph of a measurable mapping , i.e. for all . For ,the set is the set of admissible actions in state at time .
-
is a stochastic transition kernel from to , i.e. for any fixed pair , the mapping is a probability measure on and is measurable for all .The quantity gives the probability that the next state at time is in if the current state is and action a is taken at time . describes the **transition law}.
-
is a measurable function. gives the (discounted) one-stage reward of the system at time if the current state is and action a is taken.
-
is a measurable mapping. gives the (discounted) terminal reward of the system at time if the state is .
An equivalent definition of MDP
A Markov Decision Model is equivalently described by the set of data with the following meaning:
-
are as in Definition of last slide
-
is the disturbance space, endowed with a -algebra .
-
is a stochastic transition kernel for and and denotes the probability that is in if the current state is and action is taken.
-
is a measurable function and is called transition or system function. gives the next state of the system at time if at time the system is in state ,action is taken and the disturbance occurs at time .
Example: Consumption Problem
We denote by the random return of our risky asset over period . Further we suppose that are non-negative, independent random variables and we assume that the consumption is evaluated by utility functions . The final capital is also evaluated by a utility function . Thus we choose the following data:
-
where denotes the wealth of the investor at time
-
where denotes the wealth which is consumed at time
-
for all , i.e. we are not allowed to borrow money
-
where denotes the random return of the asset
-
is the transition function
-
distribution of (independent of )
-
is the one-stage reward
-
-
Decision rule & strategy
-
A measurable mapping with the property for all , is called a decision rule at time . We denote by the set of all decision rules at time .
-
A sequence of decision rules with is called an -stage policy or -stage strategy.
-
-
Value function:
-
A theorem: For it holds:
Finite Horizon Markov Decision Models
Finite Horizon Markov Decision Models
**Integrability Assumption ():} For
Assumption () is assumed to hold for the -stage Markov Decision Problems.
Example: (Consumption Problem) In the consumption problem Assumption () is satisfied if we assume that the utility functions are increasing and concave and for all , because then and can be bounded by an affine-linear function with and since a.s. under every policy, the function satisfies
For and a policy let be defined by
is the expected total reward at time over the remaining stages to if we use policy and start in state at time . The value function is defined by
is the maximal expected total reward at time over the remaining stages to if we start in state at time . The functions and are well-defined since
The Bellman Equation
The Bellman Equation
Let us denote by , we define the following operators:
-
[ For define
whenever the integral exists. -
For and define
-
[ For define
is called the maximal reward operator at time .
Reward Iteration
Theorem
Let be an -stage policy. For it holds:
- and ,
- .
Example: (Consumption Problem) Note that for the operator in this example reads
Now let us assume that for all and . Moreover, we assume that the return distribution is independent of and has finite expectation . Then () is satisfied as we have shown before. If we choose the -stage policy with and , i.e. we always consume a constant fraction of the wealth, then the Reward Iteration implies by induction on that
Hence, with and maximizes the expected log-utility (among all linear consumption policies).
Maximizer, the Bellman Equation & Verification Theorem
-
Definition of a maximizer: Let . A decision is called a maximizer of at time if , i.e. for all , is a maximum point of the mapping ,
-
The Bellman Equation
-
Verification Theorem: Let be a solution of the Bellman equation. Then it holds:
-
for .
-
If is a maximizer of for , then and the policy is optimal for the -stage Markov Decision Problem.
-
The Structure Assumption & Structure Theorem
-
Structure Assumption (): There exists sets and such that for all :
-
-
If then is well-defined and
-
For all there exists a maximizer of with
-
-
Structure Theorem: Let () be satisfied. Then it holds:
-
and the sequence () satisfies the Bellman equation, i.e. for
-
-
For there exit maximizers of with , and every sequence of maximizers of defines an optimal policy for the -stage Markov Decision Problem
-
-
A corollary: Let () be satisfied. If then it holds:
-
Backward Induction Algorithm
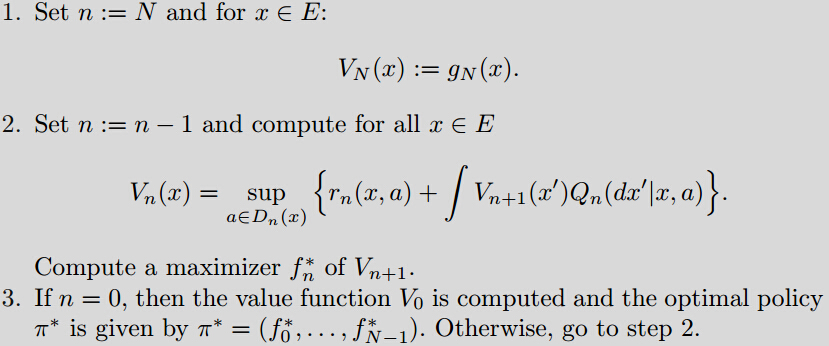
- Principle of Dynamic Programming: Let () be satisfied, Then it holds for :
i.e. if is optimal for the time period then is optimal for .
The Financial Markets
Asset Dynamics and Portfolio Strategies
Asset Dynamics and Portfolio Strategies
-
We assume that asset prices are monitored in discrete time
- time is divided into periods of length and
- multiplicative model for asset prices:
- The binomial model(\textit{Cox-Ross-Rubinstein model}) and discretization of the Black-Scholes-Merton model are two important special cases of the multiplicative model
-
In what follows we will consider an N-period financial market with risky assets and one riskless bond. We assume that all random variables are defined on a probability space with filtration () and .The financial market is given by:
- A riskless bond with and
where denotes the deterministic interest rate for the time period . If the interest rate is constant, i.e. ,then .
- There are risky assets and the price process of asset is given by and
.
The processes () are assumed to be adapted with respect to the filtration () for all . Moreover, we suppose that for all and and that is deterministic. is the relative price change in the time interval for the risky asset .
- A riskless bond with and
-
A portfolio or a trading strategy is an ()-adapted stochastic process where and for
. The quantity denotes the amount of money which is invested into asset during the time interval . -
The vector is called the initial portfolio of the investor. The value of the initial portfolio is given by
%
where denotes the inner product of the vectors and . -
Let be a portfolio strategy and denote by the value of the portfolio at time before trading. Then
-
The value of the portfolio at time after trading is given by
-
**Self-financing:} A portfolio strategy is called self-financing if
for all , i.e. the current wealth is just reassigned to the assets.
-
Arbitrage opportunity: An arbitrage opportunity is a self-financing portfolio strategy with the following property: and
-
A theorem: Consider an -period financial market. The following two statements are equivalent:
- There are no arbitrage opportunities.
- For and for all -measurable it holds:
Modeling and Solution Approaches with MDP
Modeling and Solution Approaches with MDP
-
Modeling approach: specify the elements of the MDP
- state space , action space
- transition function:
- value function
- the Bellman equation:
-
Solution approaches
- backward induction (with the Bellman equation)
- the existence and form of optimal policy
- we are interested in the structured properties that are preserved in the iterations
MDP Applications in Finance
A Cash Balance Problem
A Cash Balance Problem
The cash balance problem involves the decision about the optimal cash level of a firm over a finite number of periods. The aim is to use the firm’s liquid assets efficiently. There is a random stochastic change in the cash reserve each period (which can be both positive and negative). Since the firm does not earn interest from the cash position, there are holding cost or \textit{opportunity cost} for the cash reserve if it is positive. But also in case the cash reserve is negative the firm incurs an out-of-pocket expense and has to pay interest. The cash reserve can be increased or decreased by the management at the beginning of each period which implies transfer costs. To keep the example simple we assume that the random changes in the cash flow are given by independent and identically distributed random variables () with finite expectation. The transfer cost are linear. More precisely, let us define a function by
where . The transfer cost are then given by if the amount is transferred. The cost have to be paid at the beginning of a period for cash level . We assume that
- , ,
- is convex
Problem Formulation
-
Elements of MDP
- where denotes the cash level,
- where denotes the new cash level after transfer,
- ,
- where denotes the cash change,
- ,
- ,
- ,
-
The state transition function:
-
The value function
-
The Bellman equation
Solution
-
Solution is worked through by backward induction
-
We verified the validity of Integrability Assumption () and the relative Structure Assumption () for each
-
The solution to the cash balance problem (Theorem 2.6.2):
- There exist critical levels and such that for
with .
- There exist critical levels and such that for
- There exist critical levels and such that for
Consumption and Investment Problems
Consumption and Investment Problems
We consider now the following extension of the consumption problem of Example 2.1.4. Our investor has an initial wealth and at the beginning of each of periods she can decide how much of the wealth she consumes and how much she invests into the financial market given as in Section 4.2. In particular . The amount which is consumed at time is evaluated by a utility function . The remaining wealth is invested in the risky assets and the riskless bond, and the terminal wealth yields another utility . How should the agent consume and invest in order to maximize the sum of her expected utilities?
Formulation
-
Assumption (FM)
- There is no arbitrage opportunity.
- for all .
-
As in Section 4.2 we impose the Assumption (FM) on the financial market. Moreover, we assume that the utility functions and satisfy . Analogously to (3.1) the wealth process ()evolves as follows
where is a consumption-investment strategy, i.e. ()and ()are -adapted and . The consumption-investment problem is then given by
-
Elements of MDP
- where denotes the wealth,
- where is the amount of money invested in the risky assets and the amount which is consumed,
- is given by
- where denotes the relative risk
- ,
- .
-
The value function
Solution
-
Let and be utility functions with . Then it holds:
- There are no arbitrage opportunities if and only if there exists a measurable function such that
- is strictly increasing, strictly concave and continuous on .
- There are no arbitrage opportunities if and only if there exists a measurable function such that
-
For the multiperiod consumption-investment problem it holds:
- The value functions are strictly increasing, strictly concave and continuous.
- The value functions can be computed recursively by the Bellman equation
- There exist maximizers of and the strategy is optimal for the -stage consumption-investment problem.
Terminal Wealth Problems
Terminal Wealth Problems
Suppose we have an investor with utility function with or and initial wealth . A financial market with risky assets and one riskless bond is given (for a detailed description see Section 3.1). Here we assume that the random vectors are independent but not necessarily identically distributed. Moreover we assume that is the filtration generated by the stock prices, i.e. . We make the (FM) assumption for the financial market.
Our agent has to invest all the money into this market and is allowed to rearrange her portfolio over stages. The aim is to maximize the expected utility of her terminal wealth.
Formulation
-
The wealth process () evolves as follows
where is a portfolio strategy. The optimization problem is then
-
Elements of the MDP
- where denotes the wealth,
- where is the amount of money invested in the risky assets,
- ,
- where denotes the relative risk,
- ,
- ,
- , and .
Solution
For the multiperiod terminal wealth problem it holds:
-
The value functions are strictly increasing, strictly concave and continuous.
-
The value functions can be computed recursively by the Bellman equation
-
There exist maximizers of and the strategy is optimal for the -stage terminal wealth problem.
Portfolio Selection with Transaction Costs
Portfolio Selection with Transaction Costs
We consider now the utility maximization problem of Section 4.2 (Terminal Wealth Problems) under proportional transaction costs. For the sake of simplicity we restrict to one bond and one risky asset. If an additional amount of (positive or negative) is invested in the stock, then proportional transaction costs of are incurred which are paid from the bond position. We assume that . In order to compute the transaction costs, not only is the total wealth interesting, but also the allocation between stock and bond matters. Thus, in contrast to the portfolio optimization problems so far, the state space of the Markov Decision Model is two-dimensional and consists of the amounts held in the bond and in the stock.
Formulation
-
Elements of the MDP
- where denotes the amount invested in bond and stock,
- where denotes the amount invested in bond and stock after transaction,
- ,
- where denotes the relative price change of the stock,
- ,
- ,
- ,
- .
Dynamic Mean-Variance Problems
Dynamic Mean-Variance Problems
An alternative approach towards finding an optimal investment strategy was introduced by Markowitz in 1952 and indeed a little bit earlier by de Finetti. In contrast to utility functions the idea is now to measure the risk by the portfolio variance and incorporate this measure as follows: Among all portfolios which yield at least a certain expected return (benchmark), choose the one with smallest portfolio variance. The single-period problem was solved in the 1950s. It still has great importance in real-life applications and is widely applied in risk management departments of banks. The problem of multiperiod portfolio-selection was proposed in the late 1960s and early 1970s and has been solved recently. The difficulty here is that the original formulation of the problem involves a side constraint. However, this problem can be transformed into one without constraint by the Lagrange multiplier technique. Then we solve this stochastic Lagrange problem by a suitable Markov Decision Model.
We use the same non-stationary financial market as in Section 4.2 (Terminal Wealth Problems) with independent relative risk variables. Our investor has initial wealth . This wealth can be invested into risky assets and one riskless bond. How should the agent invest over periods in order to find a portfolio with minimal variance which yields at least an expected return of ?
Formulation
-
Elements of the MDP
- where denotes the wealth,
- where is the amount of money invested in the risky assets,
- ,
- where denotes the relative risk,
- ,
- distribution of (independent of ).
-
The original formulation (MV)
-
An equivalent formulation (MV)
-
Assumption (FM):
- and for all .
- The covariance matrix of the relative risk process
is positive definite for all . - .
-
Problem (MV) can be solved via the well-known Lagrange multiplier tecnique. Let be the Lagrange-function, i.e.
-
The Lagrange-problem for the parameter
-
A stochastic LQ-problem
If is optimal for ,then is optimal for with . -
Elements od MDP
- ,
-
Solution

-
Dynamic Mean-Risk Problems
Index Tracking
Index Tracking
The problem of index-tracking which is formulated below can be seen as an application of mean-variance hedging in an incomplete market. Suppose we have a financial market with one bond and d risky assets as in Section 3.1. Besides the tradeable assets there is a non-tradable asset whose price process
evolves according to
.
The positive random variable which is the relative price change of the non-traded asset may be correlated with . It is assumed that the random vectors are independent and the joint distribution of is given. The aim now is to track the non-traded asset as closely as possible by investing into the financial market. The tracking error is measured in terms of the quadratic distance of the portfolio wealth to the price process , i.e. the optimization problem is then
where is -measurable.
Formulation
-
Elements of the MDP
- where and is the wealth and the value of the non-traded asset,
- where is the amount of money invested in the risky assets,
- ,
- where and is the relative risk of the traded assets and is the relative price change of the non-traded asset.
- The transition function is given by
- joint distribution of (independent of ),
- .
-
Value function (cost-to-go)