L05a Neural Networks for Structured Data
Materials are adopted from "Murphy, Kevin P. Probabilistic machine learning: an introduction. MIT press, 2022.". This handout is only for teaching. DO NOT DISTRIBUTE.
- L05a Neural Networks for Structured Data
Introduction
So far, we have learned:
-
linear input-output mapping
- logistic regression:
- multiclass case:
- linear regression:
- generalized linear models: Poisson dist. etc.
- logistic regression:
-
models/algorithms linear in parameters
- feature transformation, by replacing with
- polynomial transform (in ):
-
deep neural networks or DNNs
- to endow the feature extractor with its own parameters,
- and
- repeat this process recursively, to create more and more complex functions
- where is the function at layer
- to endow the feature extractor with its own parameters,
-
The term "DNN" actually encompasses a larger family of models, in which we compose differentiable functions into any kind of DAG (directed acyclic graph, 有向无环图), mapping input to output.
- feedforward neural network (FFNN) or multilayer perceptron (MLP): the DAG is a chain.
- A MLP is for "structured data" or "tabular data":
- each column (feature) has a specific meaning
-
DNNs for “unstructured data”
- “unstructured data”: images, text
- the input data is variable sized
- each individual element (e.g., pixel or word) is often meaningless on its own
- DNNs
- convolutional neural networks (CNN) images
- recurrent neural networks (RNN) and transformers sequences
- graph neural networks (GNN) graphs.
- “unstructured data”: images, text
Multilayer perceptrons (MLPs)
- perceptron (感知机)
- is a deterministic version of logistic regression
- the functional form:
- : the heaviside step function, also known as a linear threshold function
- perceptrons are very limited in what they can represent due to their linear decision boundaries
The XOR problem
- to learn a function that computes the exclusive OR (异-或逻辑) of its two binary inputs
- The truth table (真值表) for the function
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
-
It is clear that the data is not linearly separable, so a perceptron cannot represent this mapping.
-
this problem can be overcome by stacking multiple perceptrons on top of each other: multilayer perceptron (MLP)
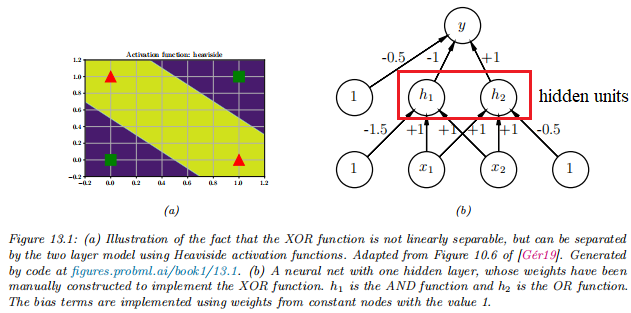
-
first hidden unit (AND operation) computes :
- functional form:
- are the weights
- is the bias (偏置)
- will fire iff and are both on
- functional form:
-
the second hidden unit (OR operation) computes
-
the third unit computes the output
- where is the NOT (logical negation) operation
- the value
-
This is equivalent to the XOR function
An MLP can represent any logical function. However, we obviously want to avoid having to specify the weights and biases by hand. In the rest of this chapter, we discuss ways to learn these parameters from data.
Differentiable MLPs
- MLPs are difficult to train
- the heaviside function is non-differentiable
- A natural solution: replacing the heaviside function with a differeentiable one (i.e. the activation function )
- the big idea:
-
define the hidden units at each layer to be a linear transformation of the hidden units at the previous layer passed elementwise through this activation function
- functional form
- in scalar form,
- functional form
-
pre-activations: The quantity that is passed to the activation function
- .
-
backpropagation (反向传播算法):
- compose of these functions together
- compute the gradient of the output wrt the parameters in each layer using the chain rule
- pass the gradient to an optimizer to minimize some training objective
-
Activation functions (激活函数)
-
linear activation function, , makes the whole model reduces to a regular linear model
-
nonlinear activation functions.
- sigmoid (logistic) function
- a smooth approximation to the Heaviside function used in a perceptron:
- it saturates(饱和) at 1 for large positive inputs, and at 0 for large negative inputs
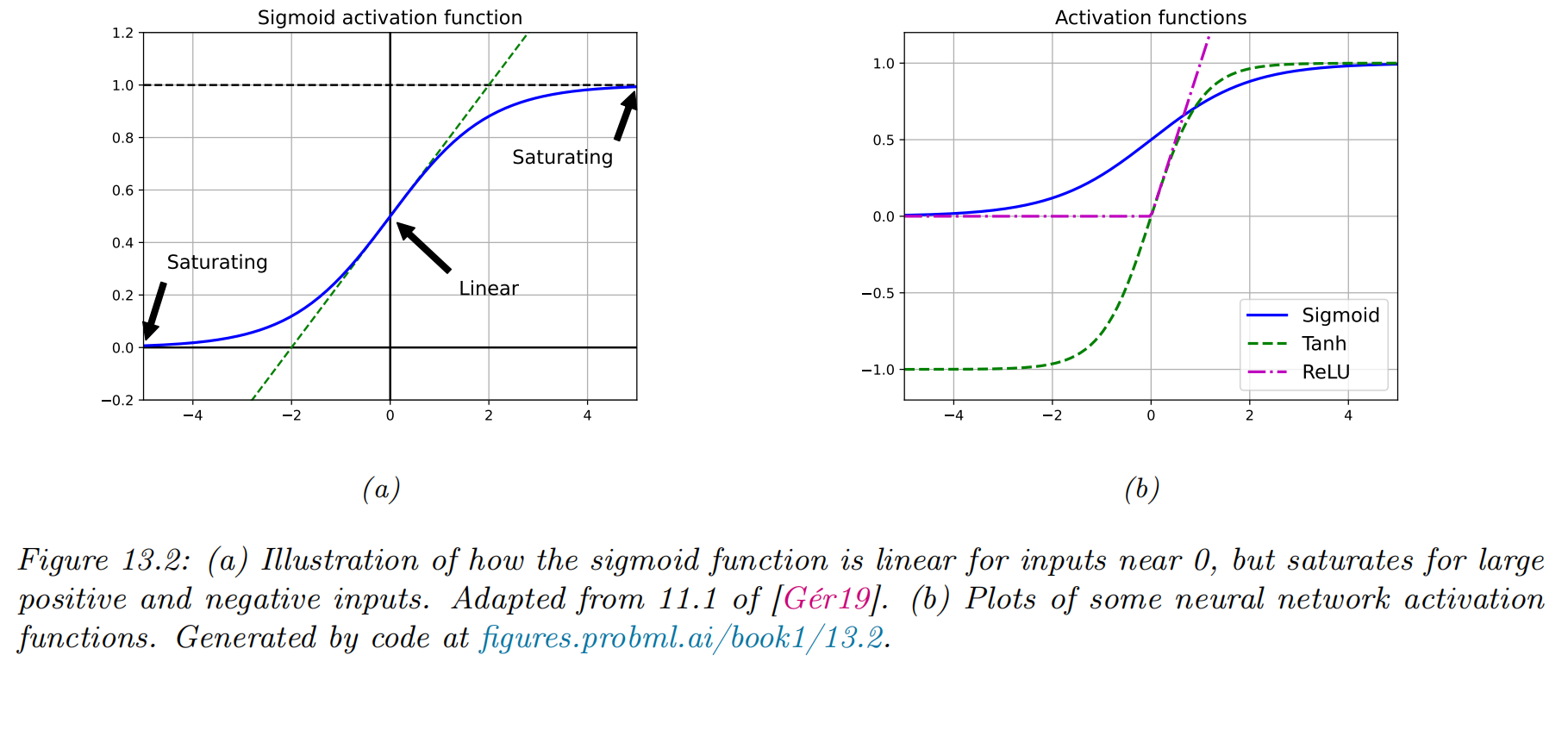
- 因为Logistic函数的性质,使得装备了Logistic激活函数的神经元具有以下两点性质:
- 其输出直接可以看作是概率分布,使得神经网络可以更好地和统计学习模型进行结合。
- 其可以看作是一个软性门(Soft Gate),用来控制其它神经元输出信息的数量。
- a smooth approximation to the Heaviside function used in a perceptron:
- the tanh function(双曲正切函数)
- Tanh 函数可以看作是放大并平移的 Logistic 函数,其值域是 。
- has a similar shape
- saturates at and
- Tanh 函数的输出是零中心化的(Zero-Centered),而 Logistic 函数的输出恒大于 0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
- Tanh 函数可以看作是放大并平移的 Logistic 函数,其值域是 。
- vanishing gradient problem
- the gradient of the output wrt the input will be close to zero
- any gradient signal from higher layers will not be able to propagate back to earlier layers
- it makes it hard to train the model using gradient descent
- rectified linear unit(修正线性单元) or ReLU
- a non-saturating activation functions
- make it possible to train very deep models
- it "turns off" negative inputs, and passes positive inputs unchanged
- sigmoid (logistic) function
Example models
MLPs can be used to perform classification and regression for many kinds of data. We give some examples below.
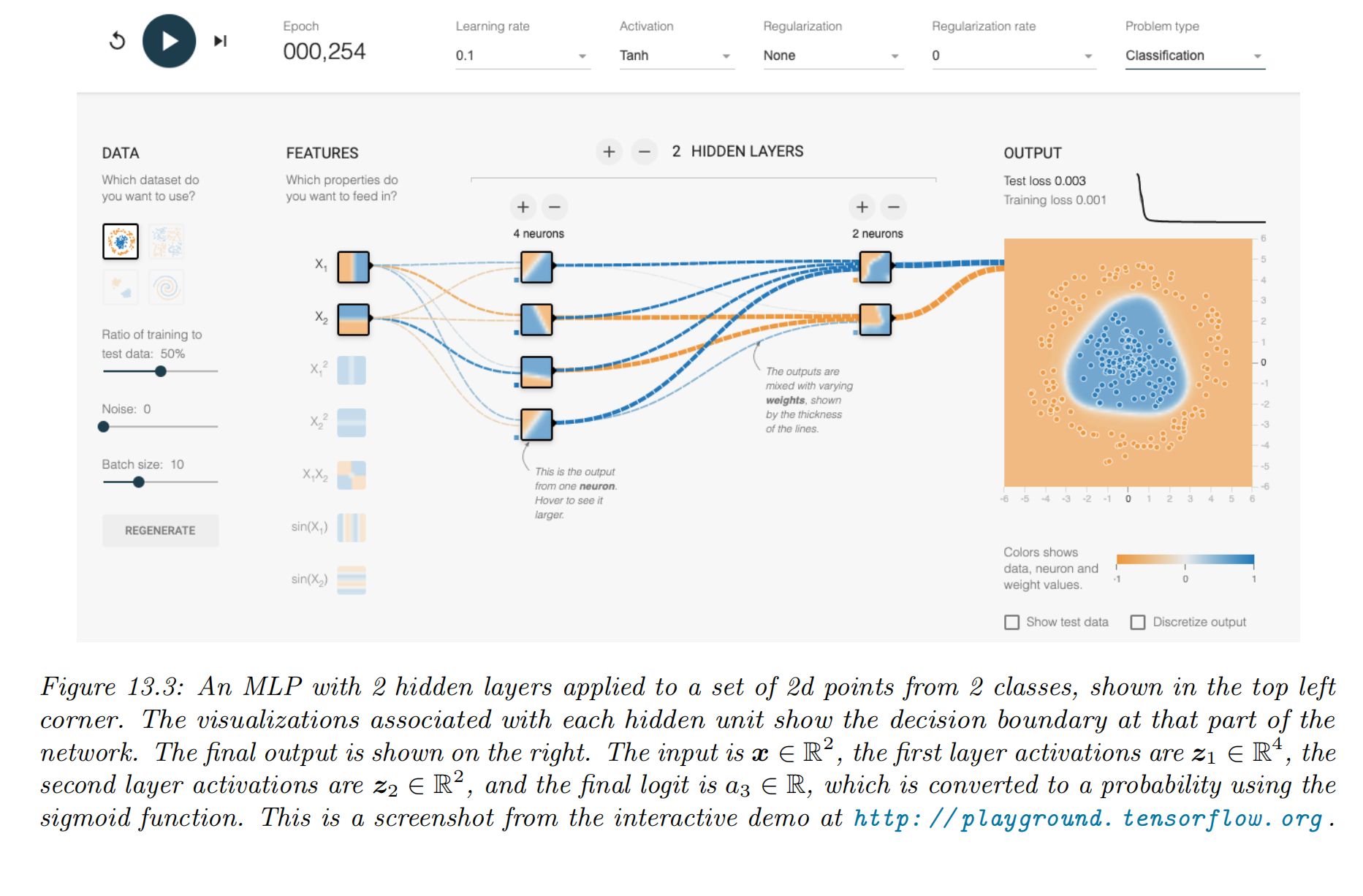
Try it for yourself via: https://playground.tensorflow.org
MLP for classifying data into 2 categories
an MLP with two hidden layers applied to a 2 d input vector (Figure )
- the model:
- is the final logit score, which is converted to a probability via the sigmoid (logistic) function.
- layer 2 is computed by taking a nonlinear combination of the 4 hidden units in layer 1 , using
- layer 1 is computed by taking a nonlinear combination of the 2 input units, using
- By adjusting the parameters, , to minimize the negative log likelihood, we can fit the training data very well
MLP for image classification
- "flatten" the 2 d input into 1 d vector: dimensional
- NN structure: use 2 hidden layers with 128 units each, followed by a final 10 way softmax layer

- training results
- train for just two "epochs" (passes over the dataset)
- test set accuracy of
- the errors seem sensible, e.g., 9 is mistaken as a 3
- Training for more epochs can further improve test accuracy

MLP for text classification
- convert the variable-length sequence of words into a fixed dimensional vector
- each is a one-hot vector of length
- is the vocabulary size
- the method
- treat the input as an unordered bag of words
- the first layer of the model is a embedding matrix , which converts each sparse -dimensional vector to a dense -dimensional embedding,
- convert this set of -dimensional embeddings into a fixed-sized vector using global average pooling,
- example:
- a single hidden layer
- a logistic output (for binary classification), we get
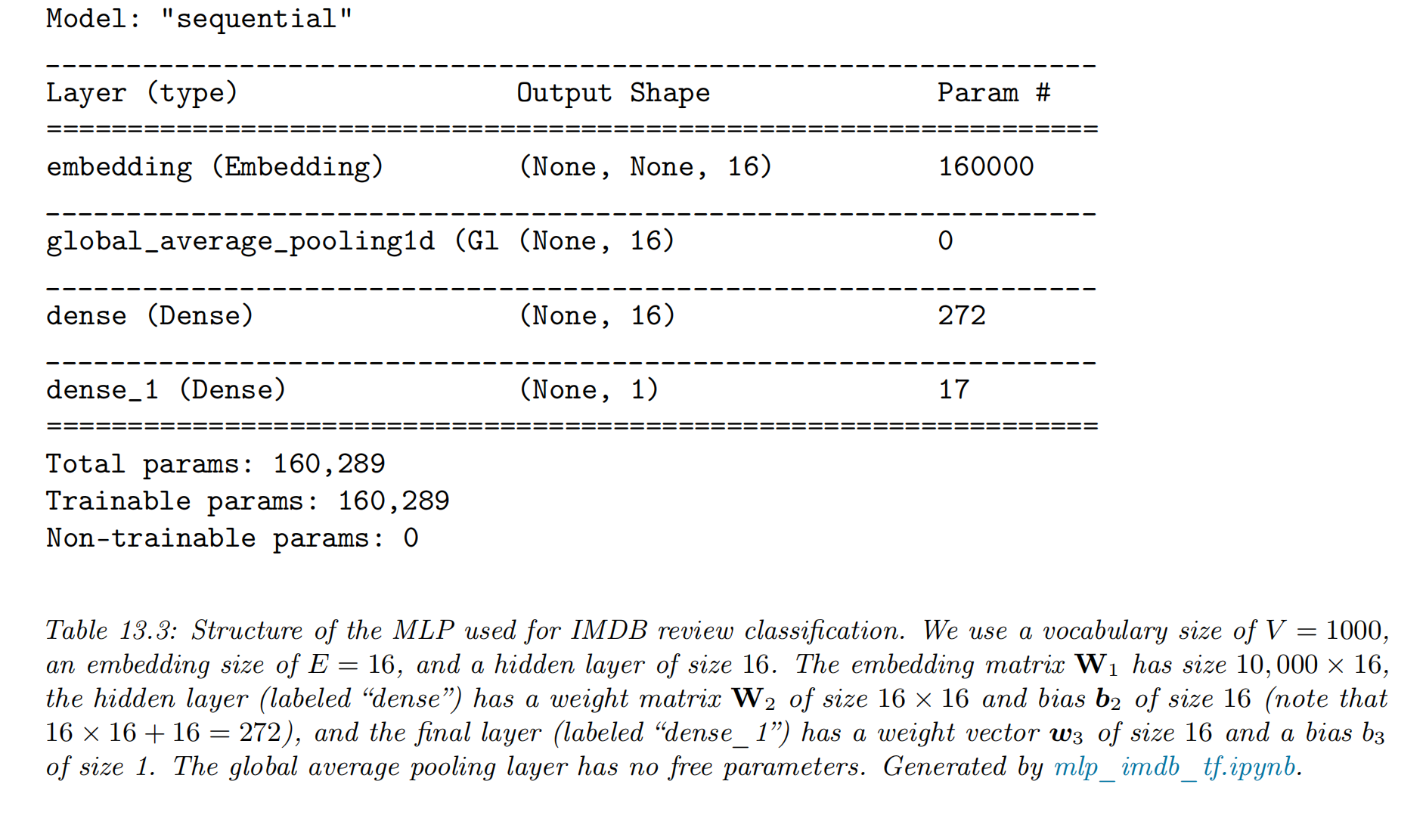
- NN setting & the training result
- vocabulary size:
- embedding size of
- hidden layer of size 16
- we get on the validation set.
MLP for heteroskedastic regression

- a model for heteroskedastic nonlinear regression
- outputs:
- .
- The two heads:
- the head, we use a linear activation,
- the head, we use a softplus activation, .
- linear heads and a nonlinear backbone, the overall model is given by

- stochastic volatility model
- properties
- the mean grows linearly over time
- seasonal oscillations
- the variance increases quadratically
- applications
- financial data
- global temperature of the earth
- properties
The importance of depth
- an MLP with one hidden layer is a universal function approximator
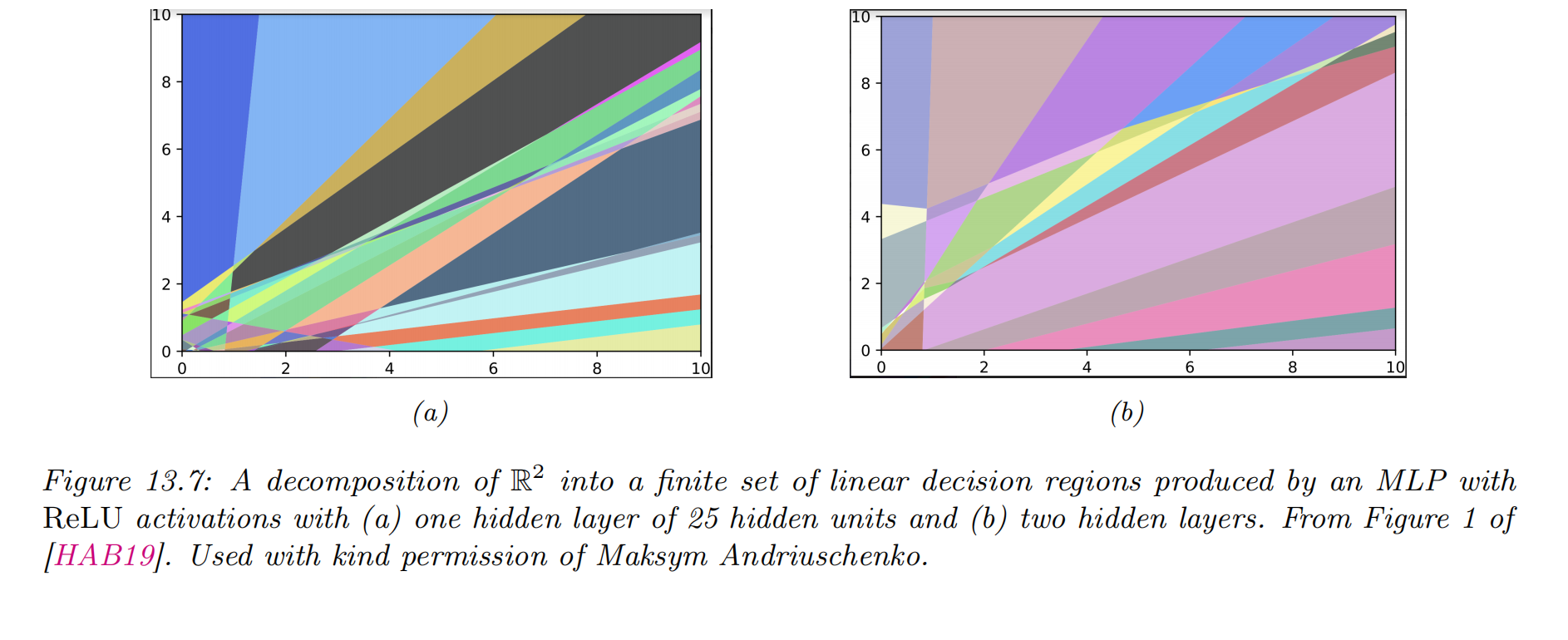
- deep networks work better than shallow ones
- the benefit of learning via a compositional or hierarchical way
- Example:
- classify DNA strings
- the positive class is associated with the regular expression AA??CGCG??AA
- it will be easier to learn if the model first learns to detect the AA and CG “motifs” using the hidden units in layer 1
- then uses these features to define a simple linear classifier in layer 2
The "deep learning revolution"
- some successful stories about DNNs
- automatic speech recognition (ASR)
- ImageNet image classification benchmark: reducing the error rate from 26% to 16% in a single year
- The “explosion” in the usage of DNNs
- the availability of cheap GPUs (graphics processing units)
- the growth in large labeled datasets
- high quality open-source software libraries for DNNs
- Tensorflow (made by Google)
- PyTorch (made by Facebook)
- MXNet (made by Amazon)
- PaddlePaddle 飞桨 (百度)
Connections with biology
-
McCulloch-Pitts model of the neuron (1943): , where
- the inputs
- the strength of the incoming connections
- weighted (dendrites树突) sum of the inputs
- threshold (action potential动作电位)
-
We can combine multiple such neurons together to make an artificial neural networks, ANNs
-
ANNs differs from biological brains in many ways, including the following:
-
Most ANNs use backpropagation to modify the strength of their connections while real brains do not use backprop
- there is no way to send information backwards along an axon
- they use local update rules for adjusting synaptic strengths
-
Most ANNs are strictly feedforward (前馈的), but real brains have many feedback connections
- It is believed that this feedback acts like a prior
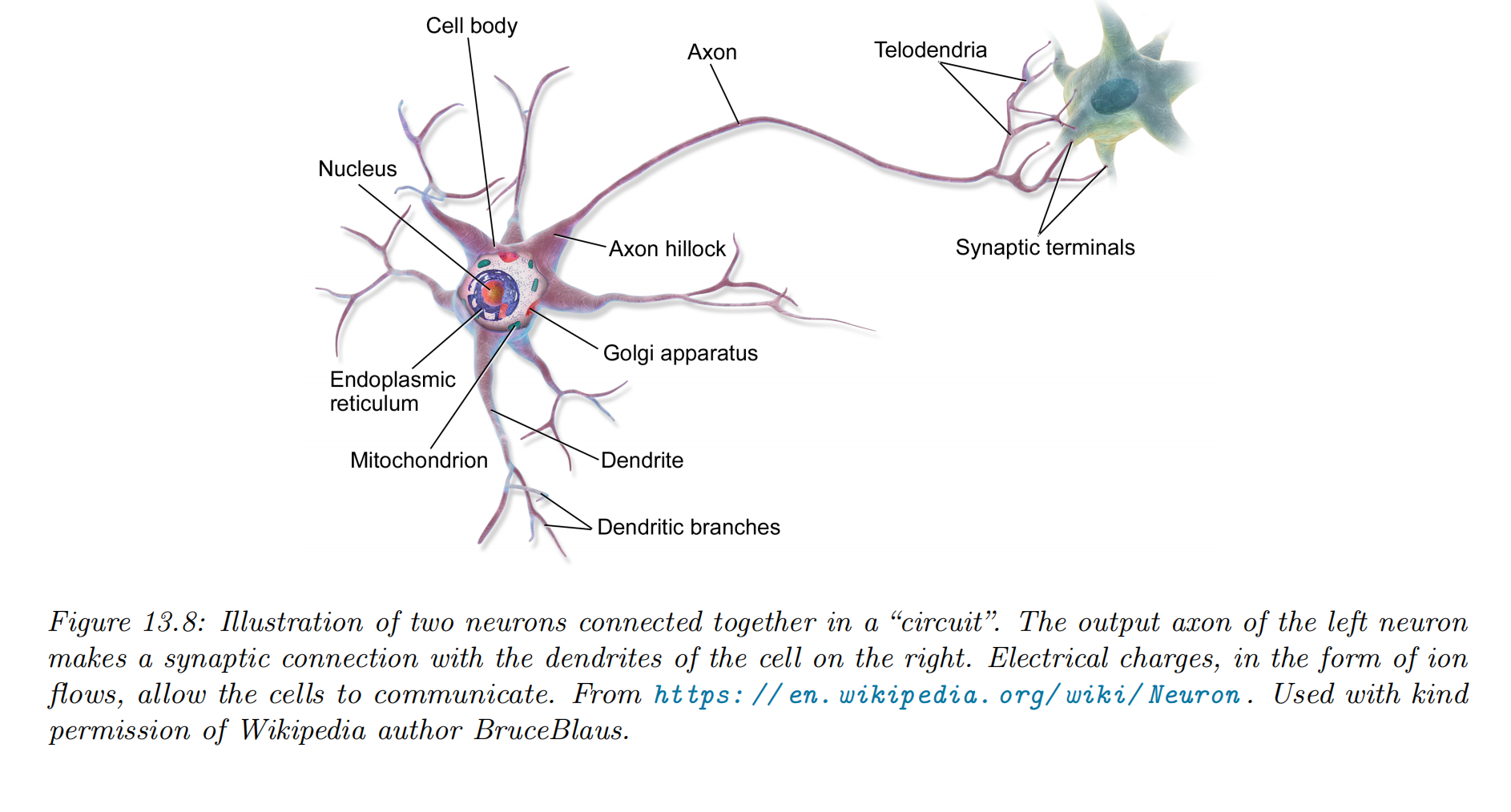
- Most ANNs use simplified neurons consisting of a weighted sum passed through a nonlinearity, but real biological neurons have complex dendritic tree structures (see Figure 13.8), with complex spatio-temporal dynamics.
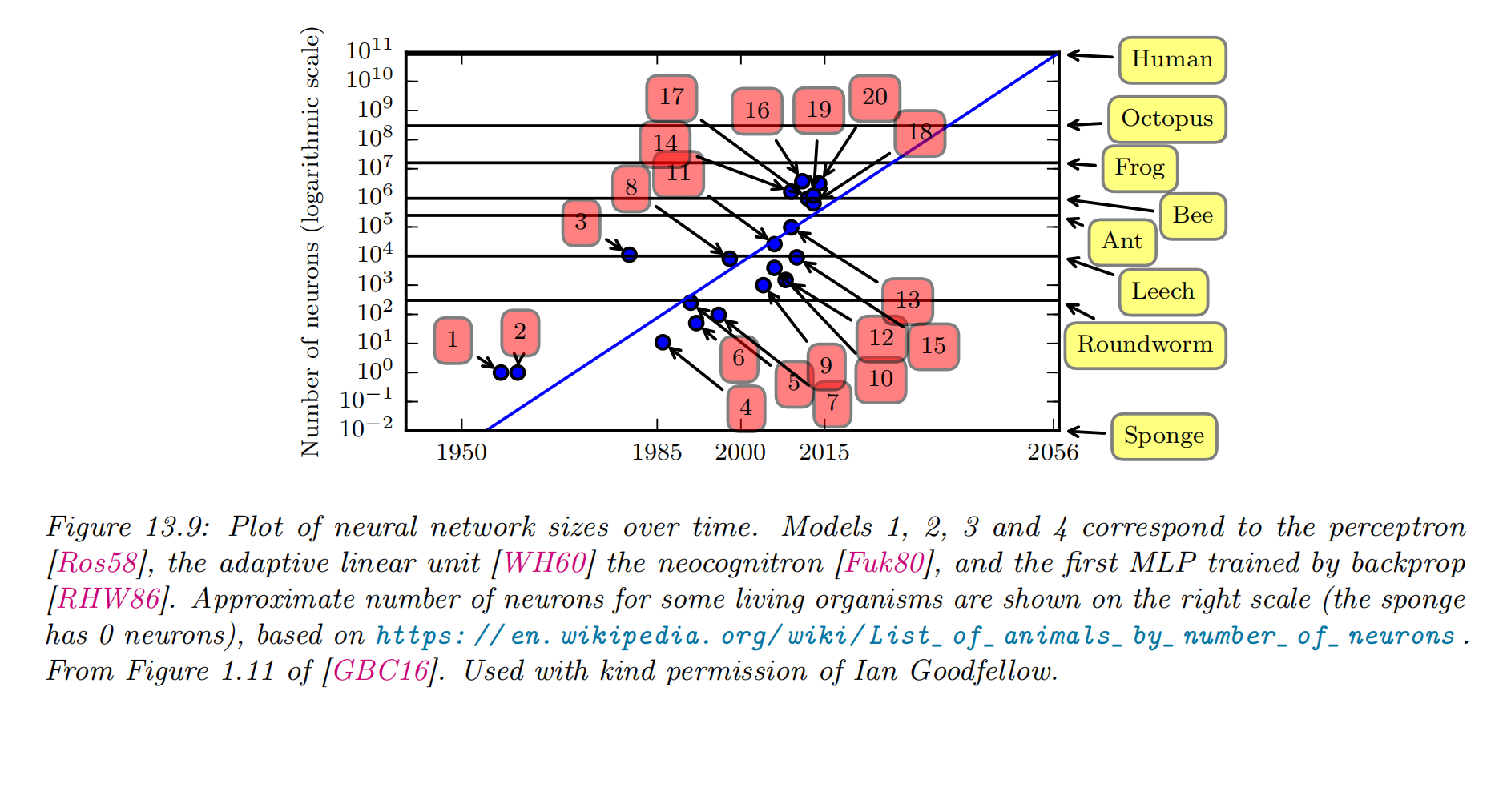
-
Most ANNs are smaller in size and number of connections than biological brains
-
Most ANNs are designed to model a single function while biological brains are very complex systems that implement different kinds of functions or behaviors
Backpropagation
- backpropagation
- simple linear chain of stacked layers: repeated applications of the chain rule of calculus
- arbitrary directed acyclic graphs (DAGs): automatic differentiation or autodiff.
Forward vs reverse mode differentiation
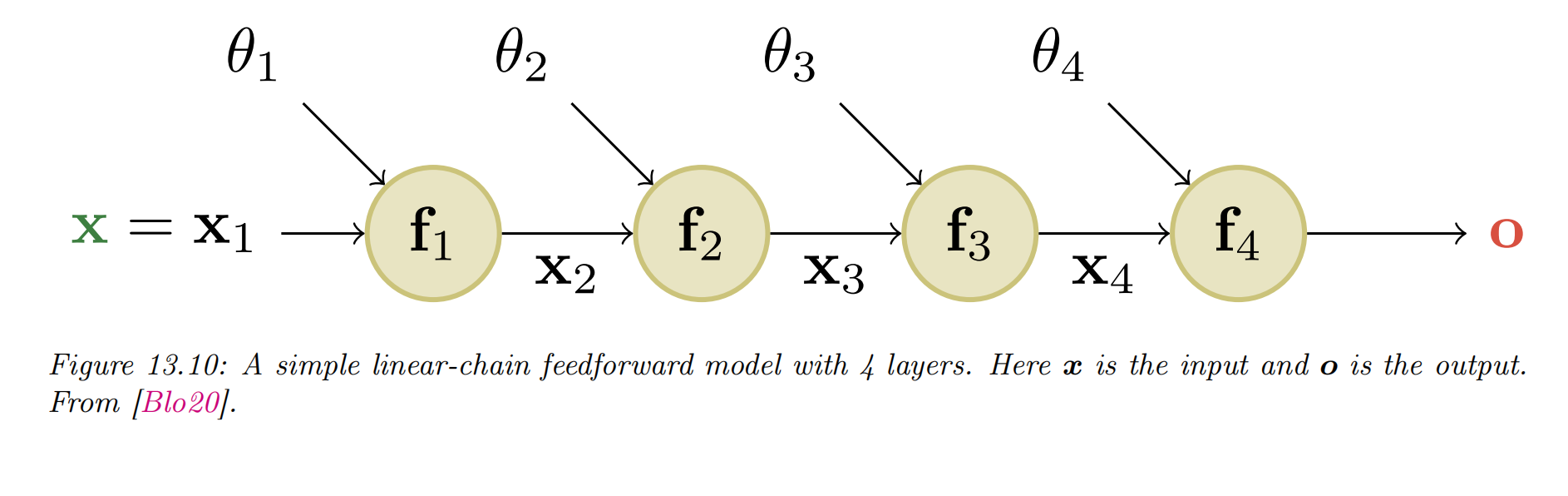
-
Consider a mapping of the form
- and
- is defined as a composition of functions:
- , and
- The intermediate steps needed to compute are , and .
-
We can compute the Jacobian using the chain rule:
-
we only need to consider how to compute the Jacobian efficiently
Computation graphs
-
Modern DNNs can combine differentiable components in much more complex ways, to create a computation graph, analogous to how programmers combine elementary functions to make more complex ones.
-
The only restriction is that the resulting computation graph corresponds to a directed ayclic graph (DAG), where each node is a differentiable function of all its inputs.
-
example
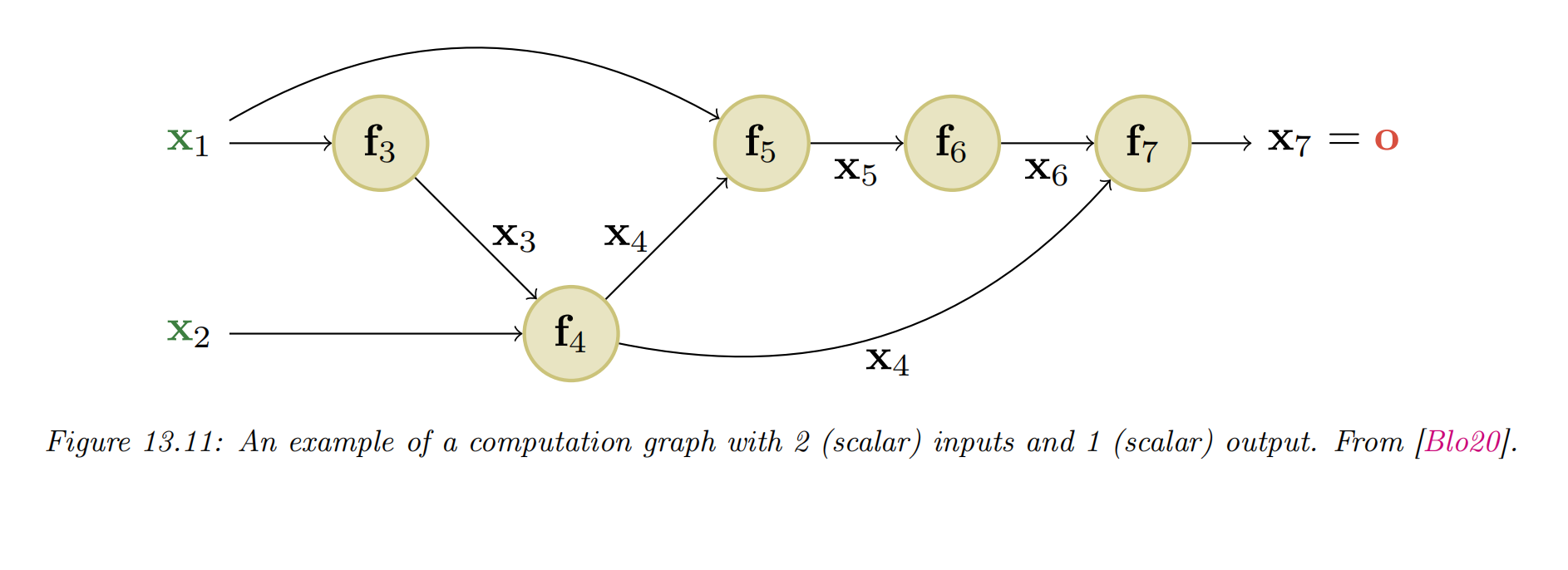
- We can compute this using the DAG in Figure 13.11, with the following intermediate functions:
- we have numbered the nodes in topological order (parents before children)
- During the backward pass, since the graph is no longer a chain, we may need to sum gradients along multiple paths. For example, since influences and , we have
- We can avoid repeated computation by working in reverse topological order. For example,
- In general, we use
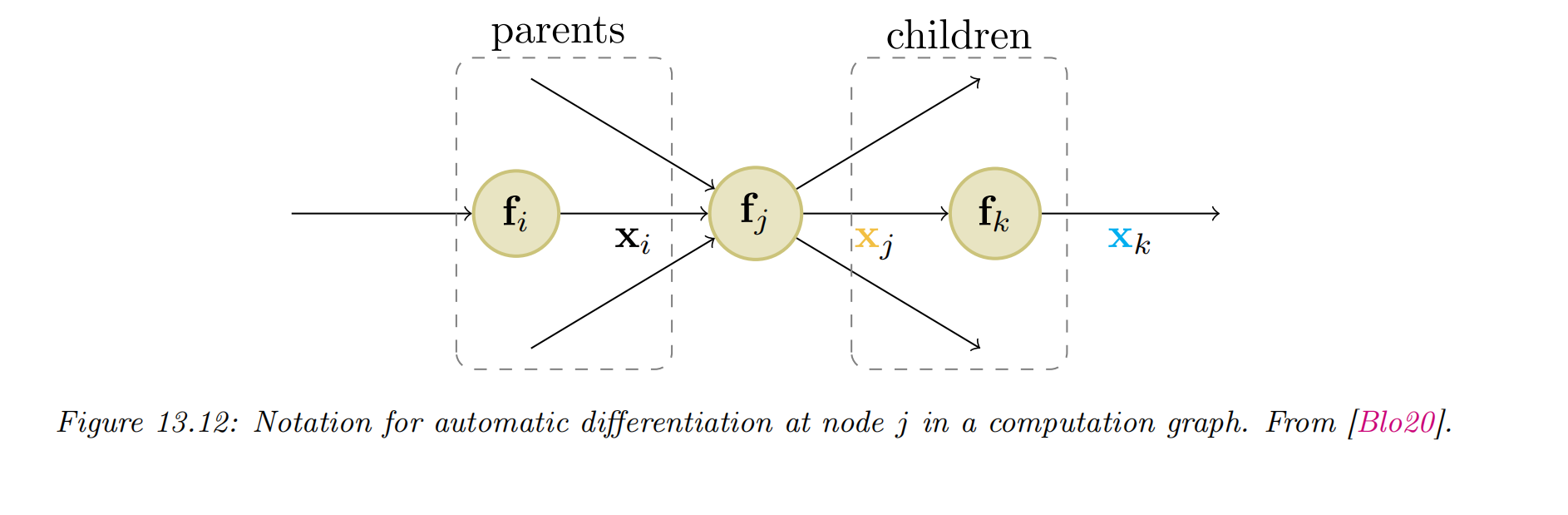
where the sum is over all children of node , as shown in Figure . The gradient vector has already been computed for each child ; this quantity is called the adjoint. This gets multiplied by the Jacobian of each child.
Training neural networks
- fit DNNs to data
- The standard approach is to use maximum likelihood estimation, by minimizing the NLL:
Tuning the learning rate
It is important to tune the learning rate (step size), to ensure convergence to a good solution. (Section 8.4.3.)
Vanishing and exploding gradients
-
vanishing gradient problem(梯度消失): When training very deep models, the gradient become very small
-
exploding gradient problem(梯度爆炸): When training very deep models, the gradient become very large
-
consider the gradient of the loss wrt a node at layer :
- is the Jacobian matrix
- is the gradient at the next layer. If is constant across layers, it is clear that the contribution of the gradient from the final layer, , to layer will be . Thus the behavior of the system depends on the eigenvectors of .
-
The exploding gradient problem can be ameliorated by gradient clipping(梯度裁剪), in which we cap the magnitude of the gradient if it becomes too large, i.e., we use
- This way, the norm of can never exceed , but the vector is always in the same direction as .
-
the vanishing gradient problem is more difficult to solve
- Modify the the activation functions at each layer to prevent the gradient from becoming too large or too small
- Modify the architecture so that the updates are additive rather than multiplicative
- Modify the architecture to standardize the activations at each layer, so that the distribution of activations over the dataset remains constant during training
- Carefully choose the initial values of the parameters
Non-saturating activation functions

reason for the gradient vanishe problem
-
setting: , where
-
for saturating activation functions
-
the gradient of the loss wrt the inputs (from an earlier layer)
-
the gradient of the loss wrt the inputs is
-
the gradient of the loss wrt the parameters is
-
if is near 0 or 1 , the gradients will go to 0 .
-
One of the keys to being able to train very deep models is to use non-saturating activation functions.
-
Several different functions have been proposed: see Table for a summary, and https://mlfromscratch.com/activation-functions-explained for more details.
| Name | Definition | Range | Reference |
|---|---|---|---|
| Sigmoid | |||
| Hyperbolic tangent | |||
| Softplus | [GBB11] | ||
| Rectified linear unit | [GBB11;KSH12] | ||
| Leaky ReLU | [MHN13] | ||
| Exponential linear unit | [CUH16] | ||
| Swish | [RZL17] | ||
| GELU | [HG16] |
ReLU
- The most common is rectified linear unit (修正线性单元) or ReLU
- The gradient has the following form:
- the gradient will not vanish, as long a is positive.
- suppose we use this in a layer to compute .
- the gradient wrt the inputs has the form
- the gradient wrt the parameters
- the “dead ReLU” problem:
- if the weights are initialized to be large and negative, then it becomes very easy for (some components of) to take on large negative values, and hence for to go to 0 .
- This will cause the gradient for the weights to go to 0 .
- The algorithm will never be able to escape this situation,
- the hidden units (components of ) will stay permanently off.
Non-saturating ReLU
-
the leaky ReLU
- .
- The slope of this function is 1 for positive inputs, and for negative inputs, thus ensuring there is some signal passed back to earlier layers, even when the input is negative.
- If we allow the parameter to be learned, rather than fixed, the leaky ReLU is called parametric ReLU
-
the Exponential Linear Unit, ELU (指数线性单元)
- This has the advantage over leaky ReLU of being a smooth function.
-
SELU (self-normalizing ELU): A slight variant of ELU
- by setting and to carefully chosen values, this activation function is guaranteed to ensure that the output of each layer is standardized (provided the input is also standardized)
- This can help with model fitting.
-
Softplus函数[Dugas et al., 2001] 可以看作是 rectifier 函数的平滑版本,其定义为:
Other choices
-
swish (do well on some image classification benchmarks)
- also called SiLU (for Sigmoid Linear Unit)
- 可看作一种软性门控机制:
- 接近1时,门处于“开”状态,激活函数的输出近似于 本身
- 接近0时,门处于“关”状态,激活函数的输出近似于0
-
Maxout单元
Maxout 单元 [Goodfellow et al., 2013] 也是一种分段线性函数。其他激活函数输入为上一层神经元的尽输入,Maxout的输入为上一层神经元的全部原始输入。每个Maxout单元有个权向量和偏置:
Maxout单元非线性函数定义为:
- Gaussian Error Linear Unit, GELU
- where is the cdf of a standard normal:
- We can think of GELU as a "soft" version of ReLU, since it replaces the step function with the Gaussian cdf, .
- the GELU can be motivated as an aptive version of dropout, where we multiply the input by a binary scalar mask, ), where the probability of being dropped is given by . Thus the expected output is
- We can approximate GELU using swish with a particular parameter setting, namely
- where is the cdf of a standard normal:
Residual connections
- residual network or ResNet (残差网络)
- One solution to the vanishing gradient problem for DNNs
- this is a feedforward model in which each layer has the form of a residual block, defined by
- is a standard shallow nonlinear mapping (e.g., linear-activation-linear).
- The inner function computes the residual term or delta that needs to be added to the input to generate the desired output
- it is often easier to learn to generate a small perturbation to the input than to directly predict the output.

- A model with residual connections has the same number of parameters as a model without residual connections, but it is easier to train
- gradients can flow directly from the output to earlier layers (Figure 13.15b)
- the activations at the output layer can be derived in terms of any previous layer using
- the gradient of the loss wrt the parameters of the 'th layer:
- Thus we see that the gradient at layer depends directly on the gradient at layer in a way that is independent of the depth of the network.
Regularization

Early stopping
- the heuristic of stopping the training procedure when the error on the validation set starts to increase
- This method works because we are restricting the ability of the optimization algorithm to transfer information from the training examples to the parameters
Weight decay
- impose a prior on the parameters, and then use MAP estimation.
- It is standard to use a Gaussian prior for the weights and biases, .
- This is equivalent to regularization of the objective.
- this is called weight decay, since it encourages small weights, and hence simpler models, as in ridge regression
Dropout
- randomly (on a per-example basis) turn off all the outgoing connections from each neuron with probability
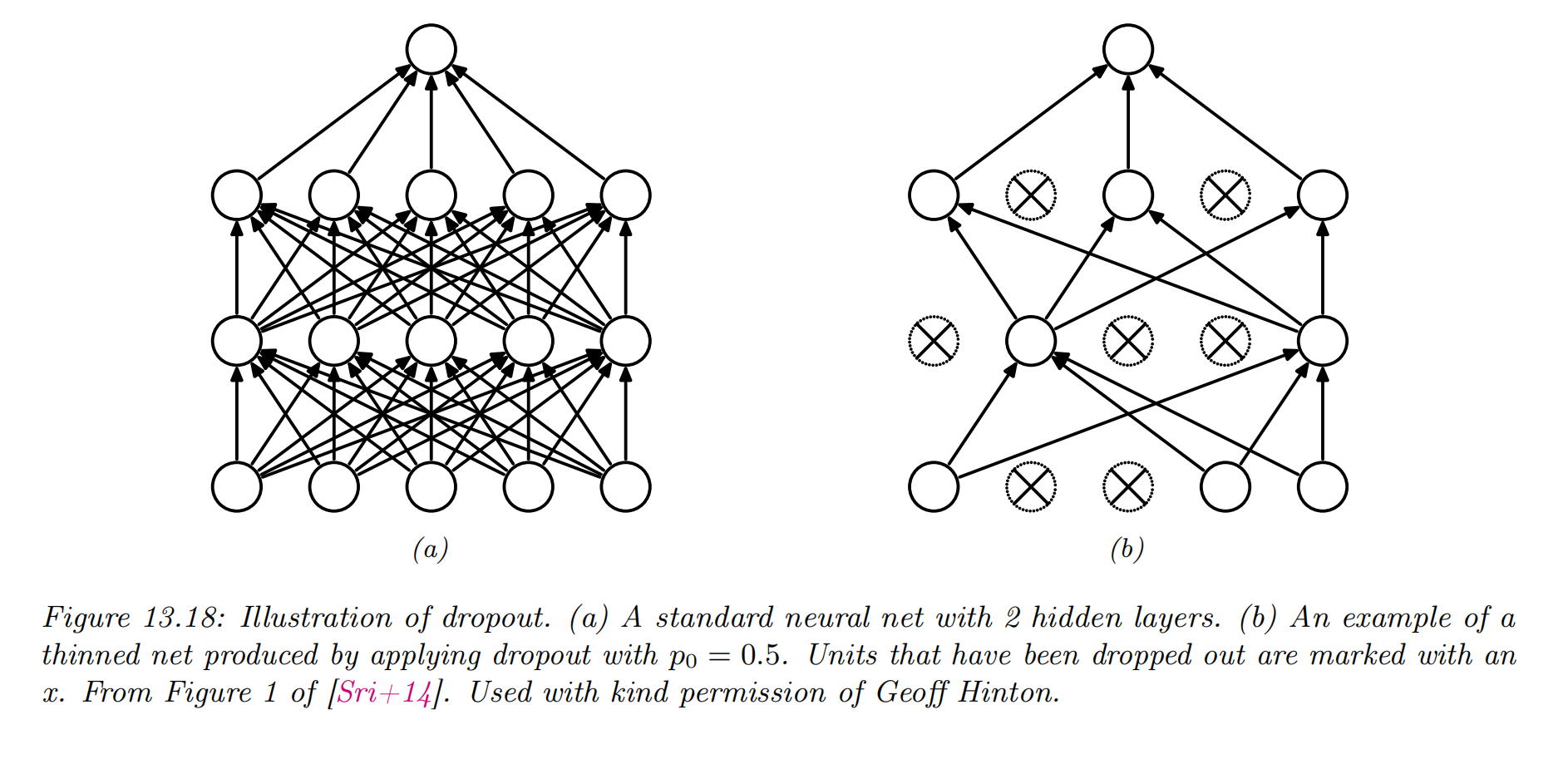
- Dropout can dramatically reduce overfitting and is very widely used.
- it prevents complex co-adaptation of the hidden units.
Bayesian neural networks
- Modern DNNs are usually trained using a (penalized) maximum likelihood objective to find a single setting of parameters.
- with large models, there are often many more parameters than data points
- there may be multiple possible models which fit the training data equally well, yet which generalize in different ways.
- It is often useful to capture the induced uncertainty in the posterior predictive distribution
- Bayesian neural network or BNN.
- It can be thought of as an infinite ensemble of differently weight neural networks.
- By marginalizing out the parameters, we can avoid overfitting.