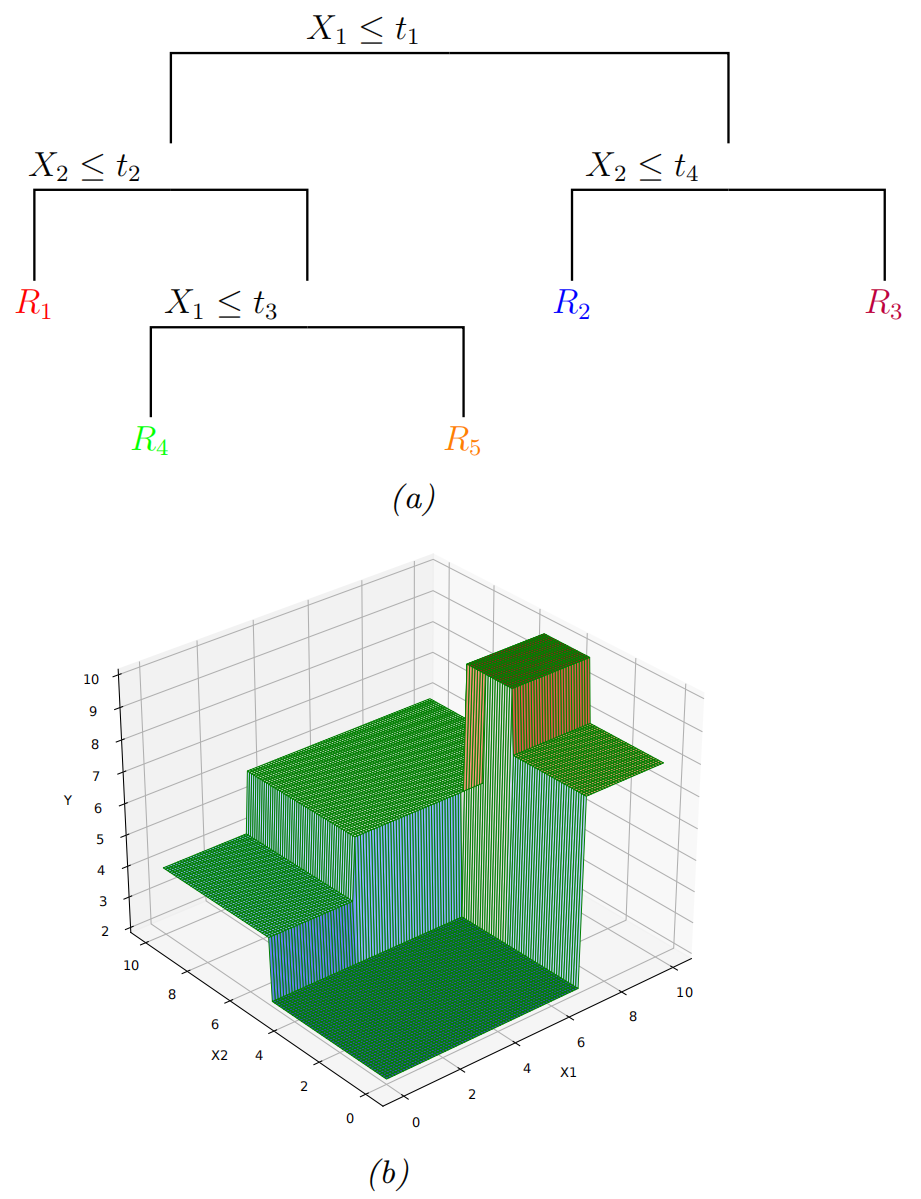
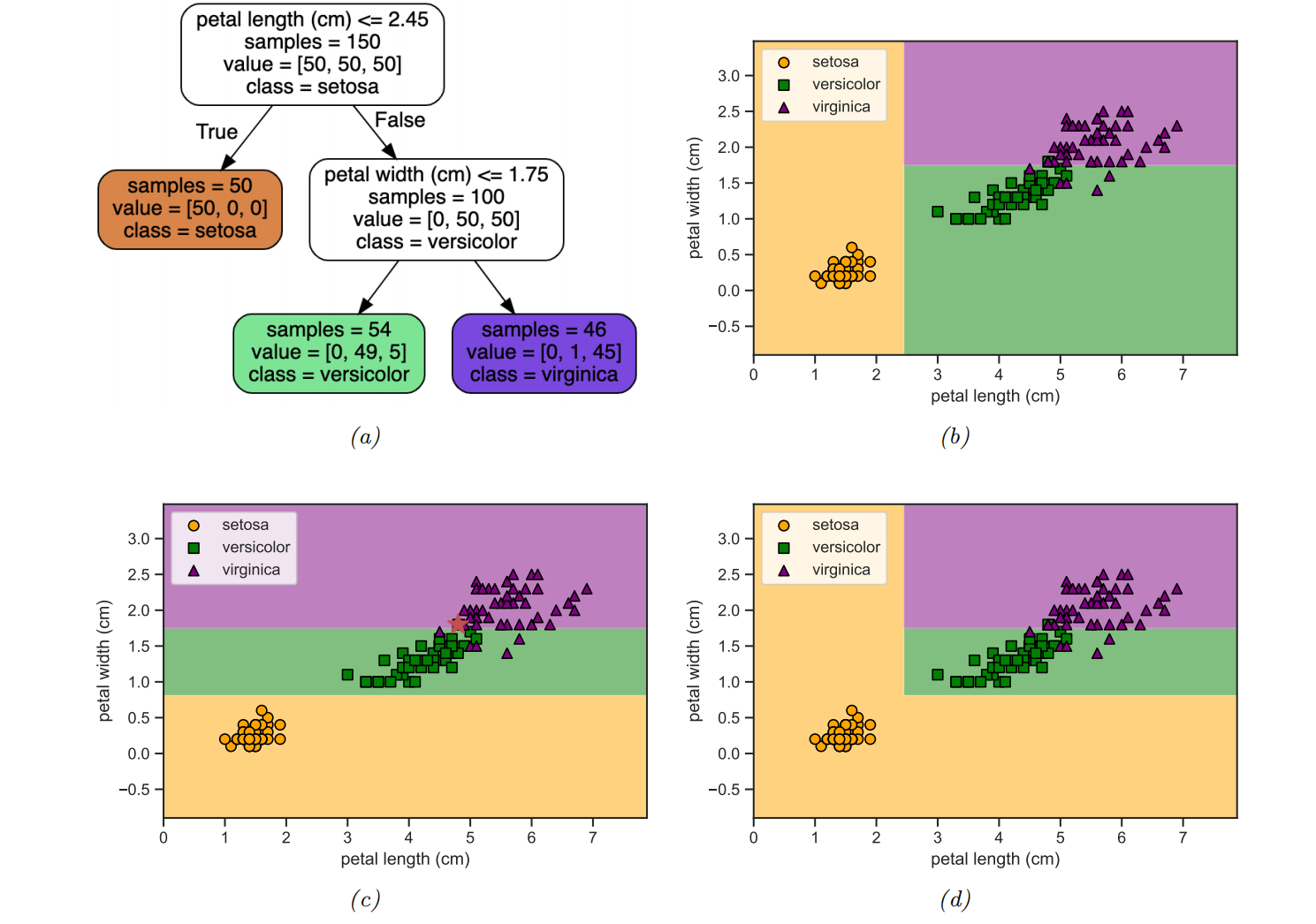
a local model in each resulting region of input space
Model definition
regression trees: all inputs are real-valued.
The tree consists of a set of nested decision rules. At each node i, the feature dimension di of the input vector x is compared to a threshold value ti, and the input is then passed down to the left or right branch, depending on whether it is above or below threshold.
At the leaves of the tree, the model specifies the predicted output for any input that falls into that part of the input space.
An example:
the region of space: R1={x:x1≤t1,x2≤t2}
the output for region 1 (mean response) can be estimated using w1=∑n=1NI(xn∈R1)∑n=1NynI(xn∈R1)
Formally, a regression tree can be defined by f(x;θ)=j=1∑JwjI(x∈Rj)
Rj is the region specified by the j'th leaf node, wj is the predicted output for that node, and θ={(Rj,wj):j=1:J}
J is the number of nodes.
The regions:
R1=[(d1≤t1),(d2≤t2)]
R2=[(d1≤t1),(d2>t2),(d3≤t3)], etc.
For categorical inputs, we can define the splits based on comparing feature di to each of the possible values for that feature, rather than comparing to a numeric threshold.
For classification problems, the leaves contain a distribution over the class labels, rather than just the mean response.
Model fitting
minimizing the following loss: L(θ)=n=1∑Nℓ(yn,f(xn;θ))=j=1∑Jxn∈Rj∑ℓ(yn,wj)
it is not differentiable
finding the optimal partitioning of the data is NP-complete
the standard practice is to use a greedy procedure, in which we iteratively grow the tree one node at a time.
three popular implementations: CART, C4.5, and ID3.
the big idea of greedy algorithms
let Di={(xn,yn)∈Ni} be the set of examples that reach node i.
If the j'the feature is a real-valued scalar
partition the data at node i by comparing to a threshold t
the set of possible thresholds Tj for feature j can be obtained by sorting the unique values of {xnj}
example: if feature 1 has the values {4.5,−12,72,−12}, then we set T1={−12,4.5,72}. For each possible threshold, we define the left and right splits, DiL(j,t)={(xn,yn)∈Ni:xn,j≤t} and DiR(j,t)={(xn,yn)∈Ni:xn,j>t}.
If the j'th feature is categorical with Kj possible values
check if the feature is equal to each of those values or not.
it defines a set of Kj possible binary splits: DiL(j,t)={(xn,yn)∈Ni : xn,j=t} and DiR(j,t)={(xn,yn)∈Ni:xn,j=t}.)
choose the best feature ji to split on, and the best value for that feature, ti, as follows: (ji,ti)=argj∈{1,…,D}mint∈Tjmin∣Di∣∣∣DiL(j,t)∣∣c(DiL(j,t))+∣Di∣∣∣DiR(j,t)∣∣c(DiR(j,t))
the cost function c(Di) of node i.
For regression, we can use the mean squared error cost(Di)=∣D∣1n∈Di∑(yn−yˉ)2
where yˉ=∣D∣1∑n∈Diyn is the mean of the response variable for examples reaching node i.
For classification, we first compute the empirical distribution over class labels for this node: π^ic=∣Di∣1n∈Di∑I(yn=c)
Given this, we can then compute the Gini index Gi=c=1∑Cπ^ic(1−π^ic)=c∑π^ic−c∑π^ic2=1−c∑π^ic2
This is the expected error rate. To see this, note that π^ic is the probability a random entry in the leaf belongs to class c, and 1−π^ic is the probability it would be misclassified.
Alternatively we can define cost as the entropy or deviance of the node: Hi=H(π^i)=−c=1∑Cπ^iclogπ^ic
A node that is pure (i.e., only has examples of one class) will have 0 entropy.
Regularization
the danger of overfitting: If we let the tree become deep enough, it can achieve 0 error on the training set (assuming no label noise), by partioning the input space into sufficiently small regions where the output is constant.
two main approaches against overfitting:
The first is to stop the tree growing process according to some heuristic, such as having too few examples at a node, or reaching a maximum depth.
The second approach is to grow the tree to its maximum depth, where no more splits are possible, and then to prune it back, by merging split subtrees back into their parent.
Pros and cons
advantages:
They are easy to interpret.
They can easily handle mixed discrete and continuous inputs.
They are insensitive to monotone transformations of the inputs (because the split points are based on ranking the data points), so there is no need to standardize the data.
They perform automatic variable selection.
They are relatively robust to outliers.
They are fast to fit, and scale well to large data sets.
They can handle missing input features.
disadvantages:
they do not predict very accurately compared to other kinds of model (the greedy nature of the tree construction algorithm).
trees are unstable: small changes to the input data can have large effects on the structure of the tree, due to the hierarchical nature of the tree-growing process, causing errors at the top to affect the rest of the tree.
Ensemble learning
Ensemble learning: reduce variance by averaging multiple (regression) models (or taking a majority vote for classifiers) f(y∣x)=∣M∣1m∈M∑fm(y∣x)
fm is the m'th base model.
The ensemble will have similar bias to the base models, but lower variance, generally resulting in improved overall performance
For classifiers: take a majority vote of the outputs. (This is sometimes called a committee method.)
suppose each base model is a binary classifier with an accuracy of θ, and suppose class 1 is the correct class.
Let Ym∈{0,1} be the prediction for the m'th model
Let S=∑m=1MYm be the number of votes for class 1
We define the final predictor to be the majority vote, i.e., class 1 if S>M/2 and class 0 otherwise. The probability that the ensemble will pick class 1 is p=Pr(S>M/2)=1−B(M/2,M,θ)
Stecking
Stecking (stacked generalization): combine the base models, by using f(y∣x)=m∈M∑wmfm(y∣x)
the combination weights used by stacking need to be trained on a separate dataset, otherwise they would put all their mass on the best performing base model.
Ensembling is not Bayes model averaging
An ensemble considers a larger hypothesis class of the form p(y∣x,w,θ)=m∈M∑wmp(y∣x,θm)
the BMA uses p(y∣x,D)=m∈M∑p(m∣D)p(y∣x,m,D)
The key difference
in the case of BMA, the weights p(m∣D) sum to one
in the limit of infinite data, only a single model will be chosen (namely the MAP model). By contrast,
the ensemble weights wm are arbitrary, and don't collapse in this way to a single model.
Bagging
bagging ("bootstrap aggregating")
This is a simple form of ensemble learning in which we fit M different base models to different randomly sampled versions of the data
this encourages the different models to make diverse predictions
The datasets are sampled with replacement (a technique known as bootstrap sampling)
a given example may appear multiple times, until we have a total of N examples per model (where N is the number of original data points).
The disadvantage of bootstrap
each base model only sees, on average, 63% of the unique input examples.
The 37% of the training instances that are not used by a given base model are called out-of-bag instances (oob).
We can use the predicted performance of the base model on these oob instances as an estimate of test set performance.
This provides a useful alternative to cross validation.
The main advantage of bootstrap is that it prevents the ensemble from relying too much on any individual training example, which enhances robustness and generalization.
Bagging does not always improve performance. In particular, it relies on the base models being unstable estimators (decision tree), so that omitting some of the data significantly changes the resulting model fit.
Random forests
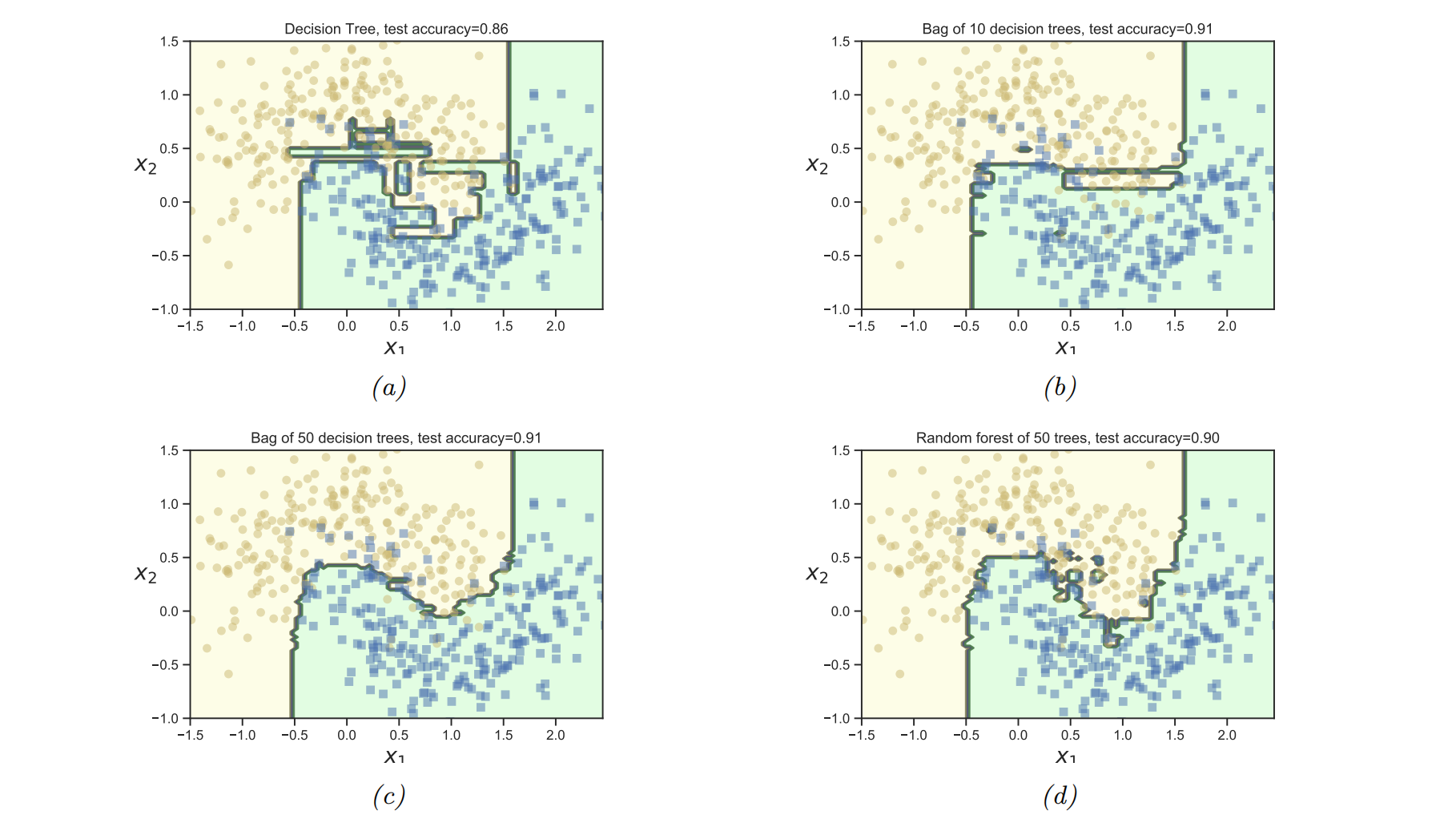
Random forests: learning trees based on a randomly chosen subset of input variables (at each node of the tree), as well as a randomly chosen subset of data cases.
Figure 18.5 shows that random forests work much better than bagged decision trees, because many input features are irrelevant.
Boosting
Ensembles of trees, whether fit by bagging or the random forest algorithm, corresponding to a model of the form f(x;θ)=m=1∑MβmFm(x;θm)
Fm is the m'th tree
βm is the corresponding weight, often set to βm=1.
additive model: generalize this by allowing the Fm functions to be general function approximators, such as neural networks, not just trees.
We can think of this as a linear model with adaptive basis functions. The goal, as usual, is to minimize the empirical loss (with an optional regularizer): L(f)=i=1∑Nℓ(yi,f(xi))
Boosting is an algorithm for sequentially fitting additive models where each Fm is a binary classifier that returns Fm∈{−1,+1}.
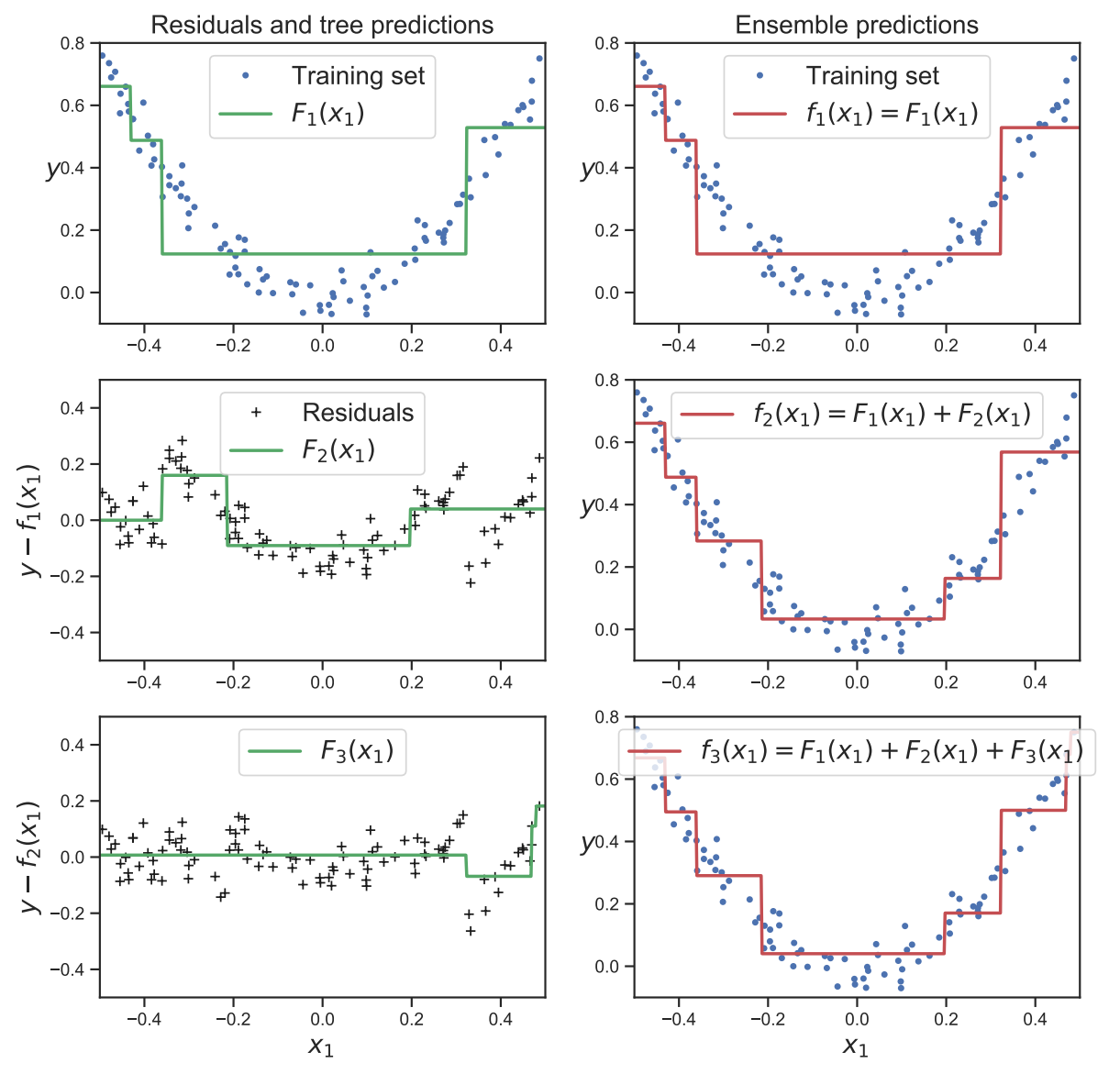
first fit F1 on the original data
weight the data samples by the errors made by F1, so misclassified examples get more weight
fit F2 to this weighted data set
keep repeating this process until we have fit the desired number M of components.
as long as each Fm has an accuracy that is better than chance (even on the weighted dataset), then the final ensemble of classifiers will have higher accuracy than any given component.
if Fm is a weak learner (so its accuracy is only slightly better than 50% )
we can boost its performance using the above procedure so that the final f becomes a strong learner.
boosting, bagging and RF
boosting reduces the bias of the strong learner, by fitting trees that depend on each other
bagging and RF reduce the variance by fitting independent trees
In many cases, boosting can work better
Forward stagewise additive modeling
forward stagewise additive modeling: sequentially optimize the objective for general (differentiable) loss functions (βm,θm)=β,θargmini=1∑Nℓ(yi,fm−1(xi)+βF(xi;θ))
We then set fm(x)=fm−1(x)+βmF(x;θm)=fm−1(x)+βmFm(x)
Quadratic loss and least squares boosting
squared error lossℓ(y,y^)=(y−y^)2
the i'th term in the objective at step m becomes ℓ(yi,fm−1(xi)+βF(xi;θ))=(yi−fm−1(xi)−βF(xi;θ))2=(rim−βF(xi;θ))2
rim=yi−fm−1(xi) is the residual of the current model on the i'th observation.
We can minimize the above objective by simply setting β=1, and fitting F to the residual errors. This is called least squares boosting.
assuming the weak learner computes p(y=1∣x)=e−F(x)+eF(x)eF(x)=1+e−2F(x)1
so F(x) returns half the log odds.
the negative log likelihood is given by ℓ(y~,F(x))=log(1+e−2y~F(x))
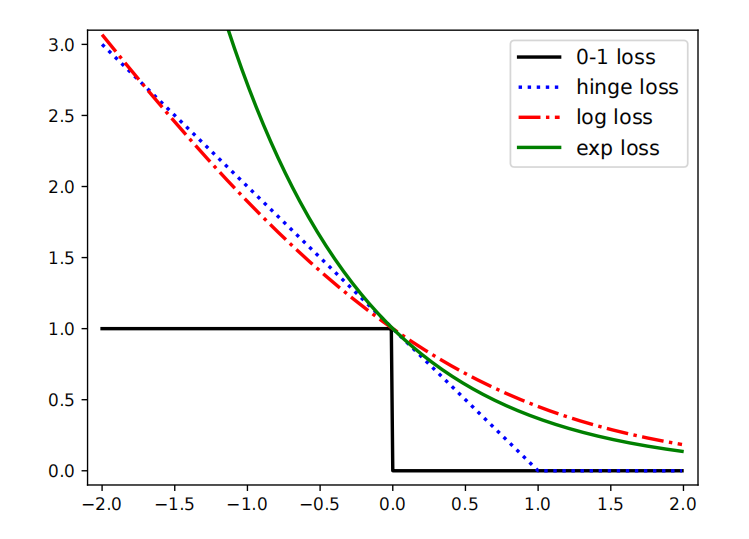
we can also use other loss functions. In this section, we consider the exponential loss ℓ(y~,F(x))=exp(−y~F(x))
this is a smooth upper bound on the 0-1 loss.
In the population setting (with infinite sample size), the optimal solution to the exponential loss is the same as for log loss. To see this, we can just set the derivative of the expected loss (for each x ) to zero: ∂F(x)∂E[e−y~f(x)∣x]=∂F(x)∂[p(y~=1∣x)e−F(x)+p(y~=−1∣x)eF(x)]=−p(y~=1∣x)e−F(x)+p(y~=−1∣x)eF(x)=0⇒p(y~=−1∣x)p(y~=1∣x)=e2F(x)
the exponential loss is easier to optimize in the boosting setting.
discrete AdaBoost
At step m we have to minimize Lm(F)=i=1∑Nexp[−y~i(fm−1(xi)+βF(xi))]=i=1∑Nωi,mexp(−βy~iF(xi))
where ωi,m≜exp(−y~ifm−1(xi)) is a weight applied to datacase i, and y~i∈{−1,+1}. We can rewrite this objective as follows: Lm=e−βy~i=F(xi)∑ωi,m+eβy~i=F(xi)∑ωi,m=(eβ−e−β)i=1∑Nωi,mI(y~i=F(xi))+e−βi=1∑Nωi,m
the optimal function to add is Fm=Fargmini=1∑Nωi,mI(y~i=F(xi))
This can be found by applying the weak learner to a weighted version of the dataset, with weights ωi,m.
Subsituting Fm into Lm and solving for β we find βm=21logerrm1−errm
where errm=∑i=1Nωi,m∑i=1Nωi,mI(y~i=Fm(xi))
the weights for the next iteration, as follows: ωi,m+1=e−y~ifm(xi)=e−y~ifm−1(xi)−y~iβmFm(xi)=ωi,me−y~iβmFm(xi)
If y~i=Fm(xi), then y~iFm(xi)=1, and if y~i=Fm(xi), then y~iFm(xi)=−1. Hence −y~iFm(xi)=2I(y~i=Fm(xo))−1, so the update becomes ωi,m+1=ωi,meβm(2I(y~i=Fm(xi))−1)=ωi,me2βmI(y~i=Fm(xi))e−βm
Since the e−βm is constant across all examples, it can be dropped. If we then define αm=2βm, the update becomes ωi,m+1={ωi,meαmωi,m if y~i=Fm(xi) otherwise
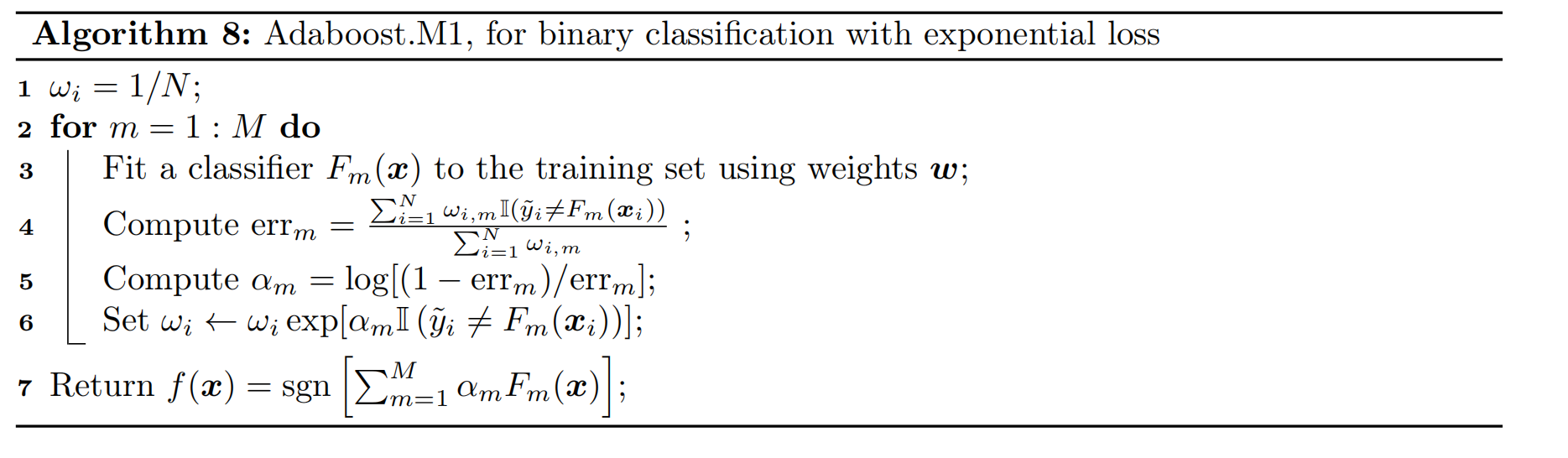
Thus we see that we exponentially increase weights of misclassified examples. The resulting algorithm shown in Algorithm 8, and is known as Adaboost.M1 [FS96].
LogitBoost
exponential loss puts a lot of weight on misclassified examples
This makes the method very sensitive to outliers (mislabeled examples).
In addition, e−y~f is not the logarithm of any pmf for binary variables y~∈{−1,+1}; consequently we cannot recover probability estimates from f(x).
A natural alternative is to use log loss. This only punishes mistakes linearly, as is clear from Figure 18.7.
Furthermore, it means that we will be able to extract probabilities from the final learned function, using p(y=1∣x)=e−f(x)+ef(x)ef(x)=1+e−2f(x)1
The goal is to minimze the expected log-loss, given by Lm(F)=i=1∑Nlog[1+exp(−2y~i(fm−1(x)+F(xi)))]
Gradient boosting
to derive a generic version, known as gradient boosting. To explain this, imagine solving f^=argminfL(f) by performing gradient descent in the space of functions. Since functions are infinite dimensional objects, we will represent them by their values on the training set, f=(f(x1),…,f(xN)). At step m, let gm be the gradient of L(f) evaluated at f=fm−1 : gim=[∂f(xi)∂ℓ(yi,f(xi))]f=fm−1
make the update fm=fm−1−βmgm
where βm is the step length, chosen by βm=βargminL(fm−1−βgm)
fitting a weak learner to approximate the negative gradient signal. That is, we use this update Fm=Fargmini=1∑N(−gim−F(xi))2
If we apply this algorithm using squared loss, we recover L2Boosting, since −gim=yi−fm−1(xi) is just the residual error. We can also apply this algorithm to other loss functions, such as absolute loss or Huber loss (Section 5.1.5.3), which is useful for robust regression problems.
For classification, we can use log-loss. In this case, we get an algorithm known as BinomialBoost [BH07]. The advantage of this over LogitBoost is that it does not need to be able to do weighted fitting: it just applies any black-box regression model to the gradient vector. To apply this to multi-class classification, we can fit C separate regression trees, using the pseudo residual of the form −gicm=∂fcm(xi)∂ℓ(yi,f1m(xi),…,fCm(xi))=I(yi=c)−πic
Although the trees are fit separately, their predictions are combined via a softmax transform p(y=c∣x)=∑c′=1Cefc′(x)efc(x)
When we have large datasets, we can use a stochastic variant in which we subsample (without replacement) a random fraction of the data to pass to the regression tree at each iteration. This is called stochastic gradient boosting [Fri99]. Not only is it faster, but it can also generalize better, because subsampling the data is a form of regularization.
Gradient tree boosting
In practice, gradient boosting nearly always assumes that the weak learner is a regression tree, which is a model of the form Fm(x)=j=1∑JmwjmI(x∈Rjm)
where wjm is the predicted output for region Rjm. (In general, wjm could be a vector.) This combination is called gradient boosted regression trees, or gradient tree boosting. (A related version is known as MART, which stands for "multivariate additive regression trees" [FM03].)
To use this in gradient boosting, we first find good regions Rjm for tree m using standard regression tree learning (see Section 18.1) on the residuals; we then (re)solve for the weights of each leaf by solving w^jm=wargminxi∈Rjm∑ℓ(yi,fm−1(xi)+w)
XGBoost
XGBoost: (https://github.com/dmlc/xgboost), which stands for "extreme gradient boosting".is a very efficient and widely used implementation of gradient boosted trees:
it adds a regularizer on the tree complexity
it uses a second order approximation of the loss instead of just a linear approximation
it samples features at internal nodes (as in random forests)
it uses various computer science methods (such as handling out-of-core computation for large datasets) to ensure scalability.
In more detail, XGBoost optimizes the following regularized objective L(f)=i=1∑Nℓ(yi,f(xi))+Ω(f)
the regularizer Ω(f)=γJ+21λj=1∑Jwj2
where J is the number of leaves, and γ≥0 and λ≥0 are regularization coefficients.
At the m'th step, the loss is given by Lm(Fm)=i=1∑Nℓ(yi,fm−1(xi)+Fm(xi))+Ω(Fm)+ const
the second order Taylor expansion: Lm(Fm)≈i=1∑N[ℓ(yi,fm−1(xi))+gimFm(xi)+21himFm2(xi)]+Ω(Fm)+ const
where him is the Hessian him=[∂f(xi)2∂2ℓ(yi,f(xi))]f=fm−1
In the case of regression trees, we have F(x)=wq(x), where q:RD→{1,…,J} specifies which leaf node x belongs to, and w∈RJ are the leaf weights. Hence we can rewrite Equation (18.49) as
follows, dropping terms that are independent of Fm : Lm(q,w)≈i=1∑N[gimFm(xi)+21himFm2(xi)]+γJ+21λj=1∑Jwj2=j=1∑J⎣⎡⎝⎛i∈Ij∑gim⎠⎞wj+21⎝⎛i∈Ij∑hi+λ⎠⎞wj2⎦⎤+γJ
where Ij={i:q(xi)=j} is the set of indices of data points assigned to the j 'th leaf.
Let us define Gjm=∑i∈Ijgim and Hjm=∑i∈Ijhim. Then the above simplifies to Lm(q,w)=j=1∑J[Gjmwj+21(Hjm+λ)wj2]+γJ
This is a quadratic in each wjm so the optimal weights are given by wj∗=−Hjm+λGjm
The loss for evaluating different tree structures q then becomes Lm(q,w∗)=−21j=1∑JHjm+λGjm2+γJ
We can greedily optimize this using a recursive node splitting procedure, as in Section 18.1. Specifically, for a given leaf j, we consider splitting it into a left and right half, I=IL∪IR. We can compute the gain (reduction in loss) of such a split as follows: gain =21[HL+λGL2+HR+λGR2−(HL+HR)+λ(GL+GR)2]−γ
where GL=∑i∈ILgim,GR=∑i∈IRgim,HL=∑i∈ILhim, and HR=∑i∈IRhim. Thus we see that it is not worth splitting a node if the gain is negative (i.e., the first term is less than γ ).
Interpreting tree ensembles
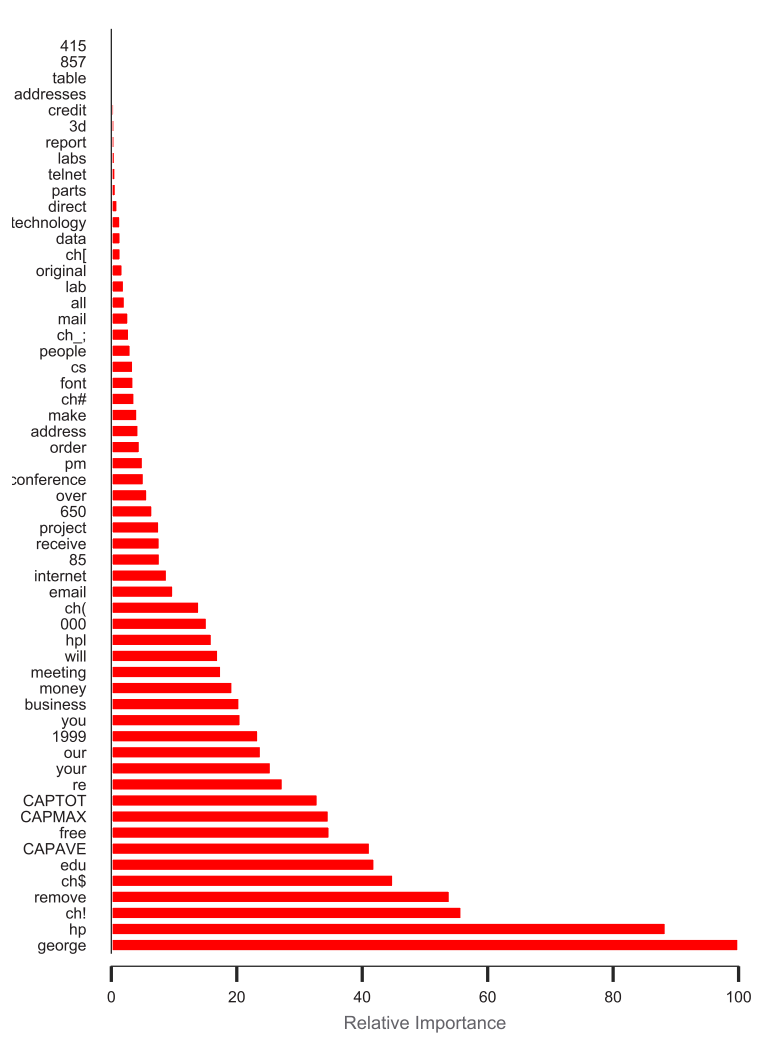
Feature importance
For a single decision tree T,[BFO84] proposed the following measure for feature importance of feature k : Rk(T)=j=1∑J−1GjI(vj=k)
the sum is over all non-leaf (internal) nodes
Gj is the gain in accuracy (reduction in cost) at node j
and vj=k if node j uses feature k.
averaging over all trees in the ensemble: Rk=M1m=1∑MRk(Tm)
normalize scores so the largest value is 100%
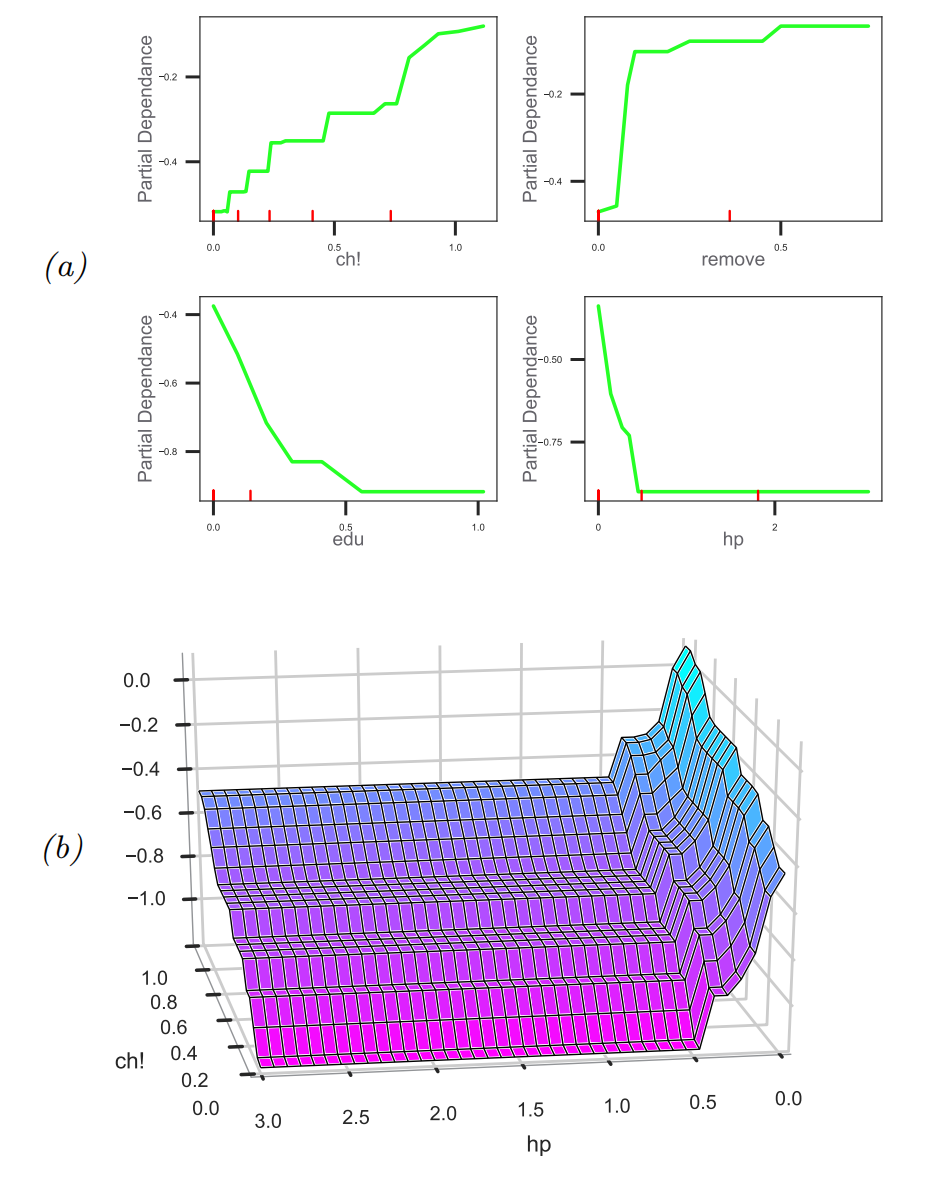
Partial dependency plots
a partial dependency plot for feature k is a plot of the following function vs xk. fˉk(xk)=N1n=1∑Nf(xn,−k,xk)
we marginalize out all features except k. In the case of a binary classifier, we can convert this to log odds, logp(y=1∣xk)/p(y=0∣xk), before plotting.
interaction effects between features j and k: fˉjk(xj,xk)=N1n=1∑Nf(xn,−jk,xj,xk)