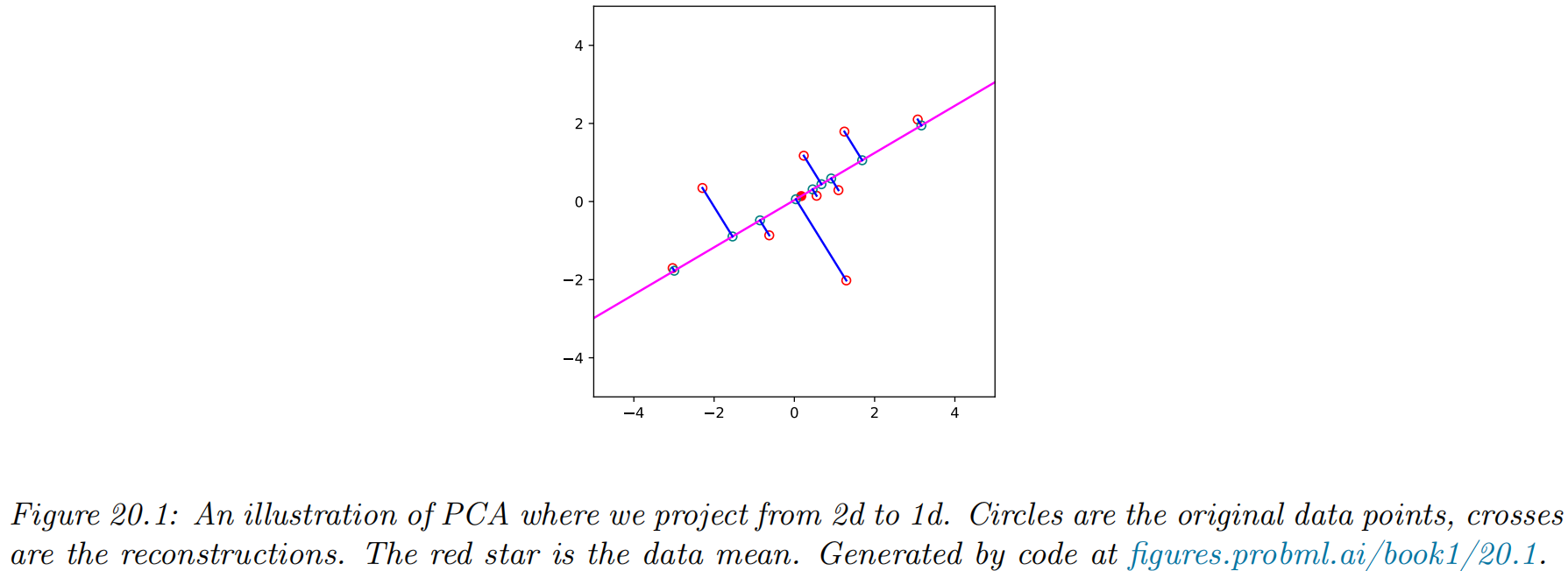
Let the coefficients for each of the data points associated with the first basis vector be denoted by z~1=[z11,…,zN1]∈RN. The reconstruction error is given by L(w1,z~1)=N1n=1∑N∥xn−zn1w1∥2=N1n=1∑N(xn−zn1w1)⊤(xn−zn1w1).=N1n=1∑N[xn⊤xn−2zn1w1⊤xn+zn12w1⊤w1]=N1n=1∑N[xn⊤xn−2zn1w1⊤xn+zn12]
Taking derivatives wrt zn1 and equating to zero gives
Plugging this back in gives the loss for the weights:
L(w1)=L(w1,z~1∗(w1))=N1n=1∑N[xn⊤xn−zn12]=const−N1n=1∑Nzn12
To solve for w1, note that L(w1)=−N1n=1∑Nzn12=−N1n=1∑Nw1⊤xnxn⊤w1=−w1⊤Σ^w1
where Σ is the empirical covariance matrix (since we assumed the data is centered). We can trivially optimize this by letting ∥w1∥→∞, so we impose the constraint ∥w1∥=1 and instead optimize L~(w1)=w1⊤Σ^w1−λ1(w1⊤w1−1)
where λ1 is a Lagrange multiplier. Taking derivatives and equating to zero we have ∂w1∂L~(w1)Σ^w1=2Σ^w1−2λ1w1=0=λ1w1
Hence the optimal direction onto which we should project the data is an eigenvector of the covariance matrix. Left multiplying by w1⊤ (and using w1⊤w1=1 ) we find w1⊤Σ^w1=λ1
Since we want to maximize this quantity (minimize the loss), we pick the eigenvector which corresponds to the largest eigenvalue.
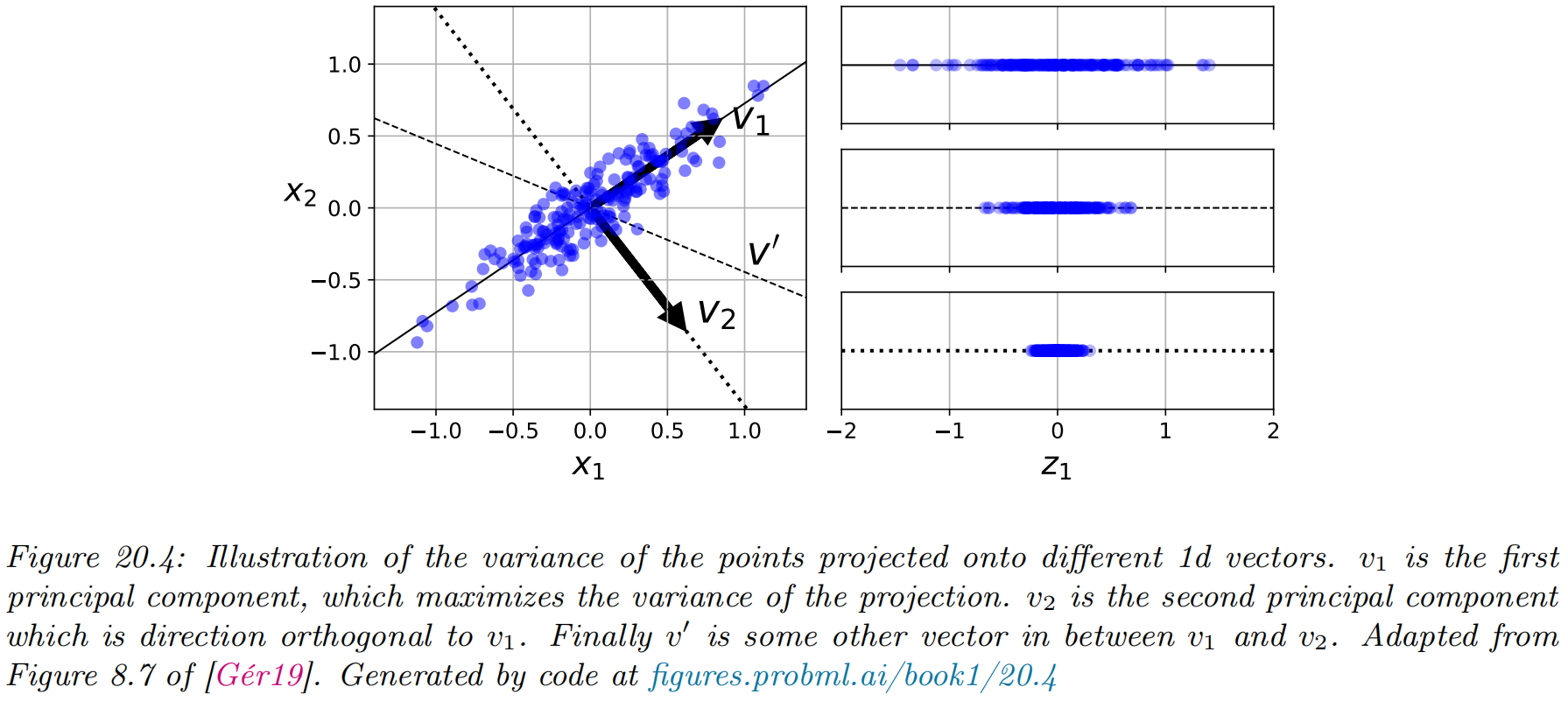
Optimal weight vector maximizes the variance of the projected data
An interesting observation: E[zn1]=E[xn⊤w1]=E[xn]⊤w1=0
The variance of the projected data is: V[z~1]=E[z~12]−(E[z~1])2=N1n=1∑Nzn12−0=−L(w1)+ const
conclusion: minimizing the reconstruction error is equivalent to maximizing the variance of the projected data: argw1minL(w1)=argw1maxV[z~1(w1)]
PCA finds the directions of maximal variance:
Induction step
Now let us find another direction w2 to further minimize the reconstruction error, subject to w1⊤w2=0 and w2⊤w2=1. The error is L(w1,z~1,w2,z~2)=N1n=1∑N∥xn−zn1w1−zn2w2∥2
Computational issues
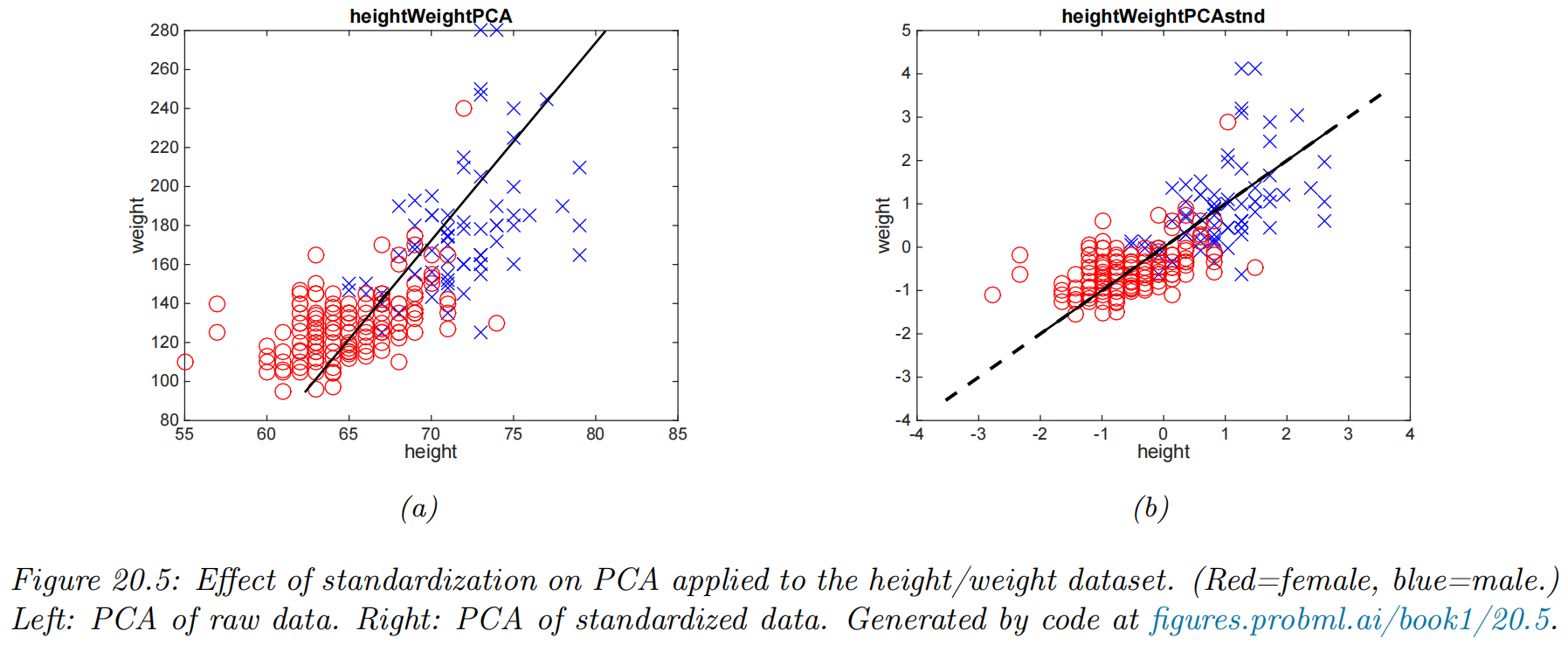
Covariance matrix vs correlation matrix
better to use the correlation matrix instead of the covariance matrix
Dealing with high-dimensional data
Finding eigenvectors of the N×N Gram matrix XX⊤ is easier than X⊤X.
let U be an orthogonal matrix containing the eigenvectors of XX⊤ with corresponding eigenvalues in Λ.
(XX⊤)U=UΛ
Pre-multiplying by X⊤ gives (X⊤X)(X⊤U)=(X⊤U)Λ
the eigenvectors of X⊤X are V=X⊤U, with eigenvalues given by Λ as before.
The normalized eigenvectors are given by V=X⊤UΛ−21
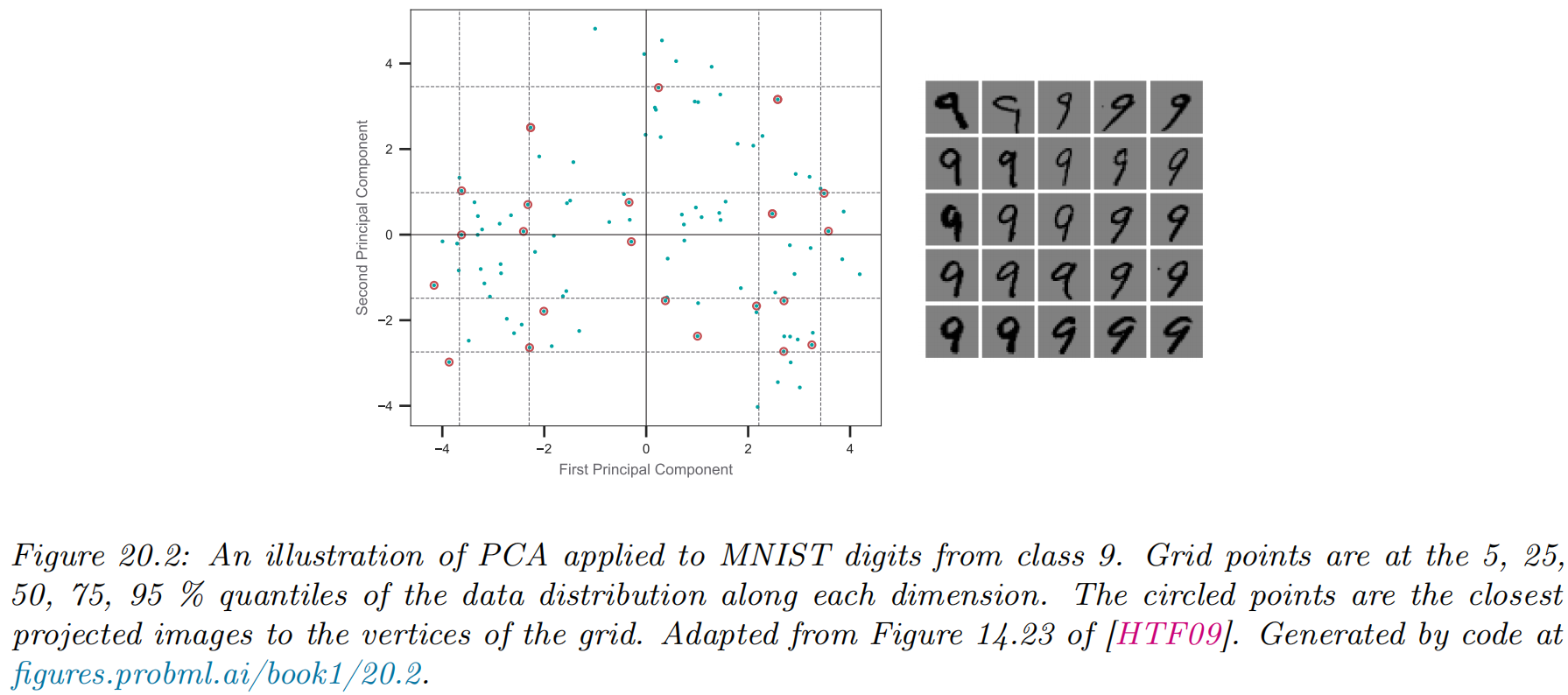
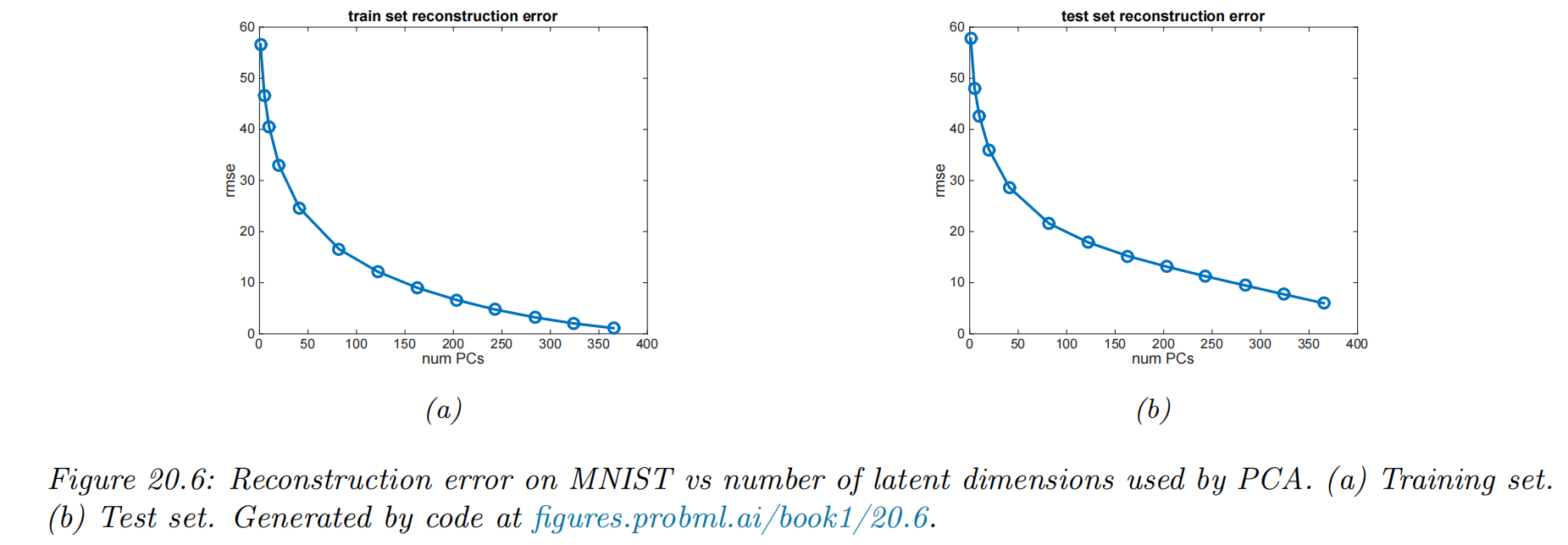
Choosing the number of latent dimensions
Reconstruction error
LL∣D∣1n∈D∑∥xn−x^n∥2
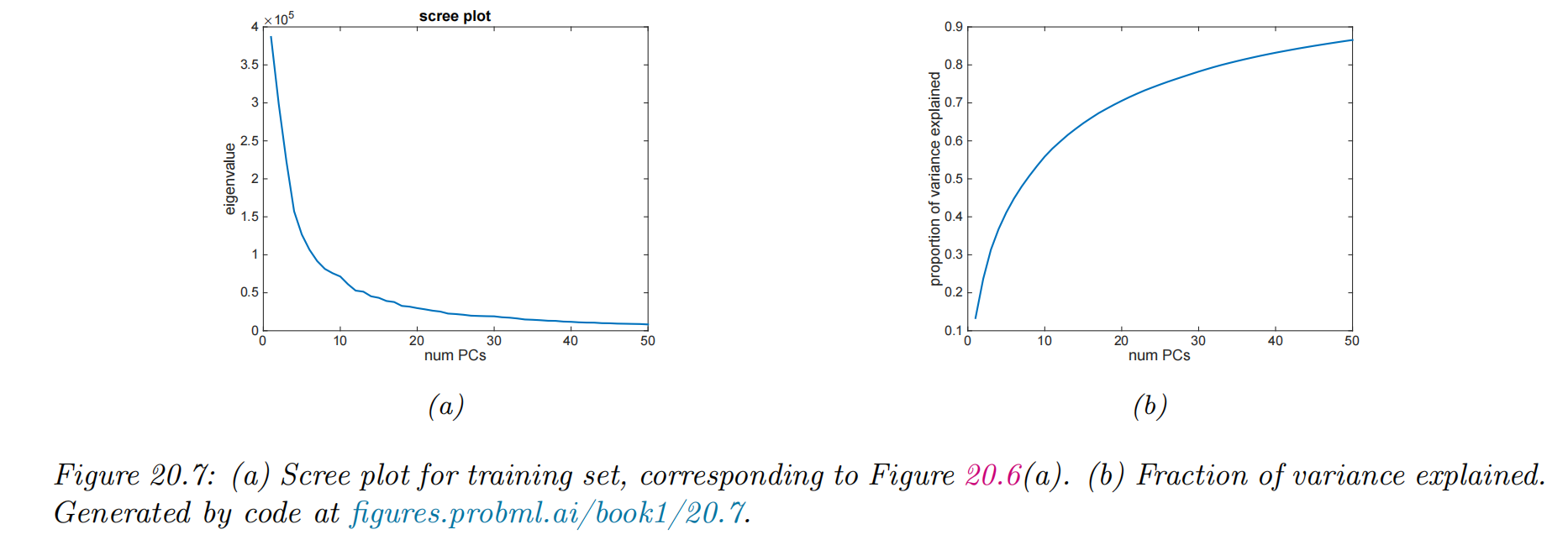
Scree plots
Lλ=j=L+1∑Dλj
FL=∑j′=1Lmaxλj′∑j=1Lλj
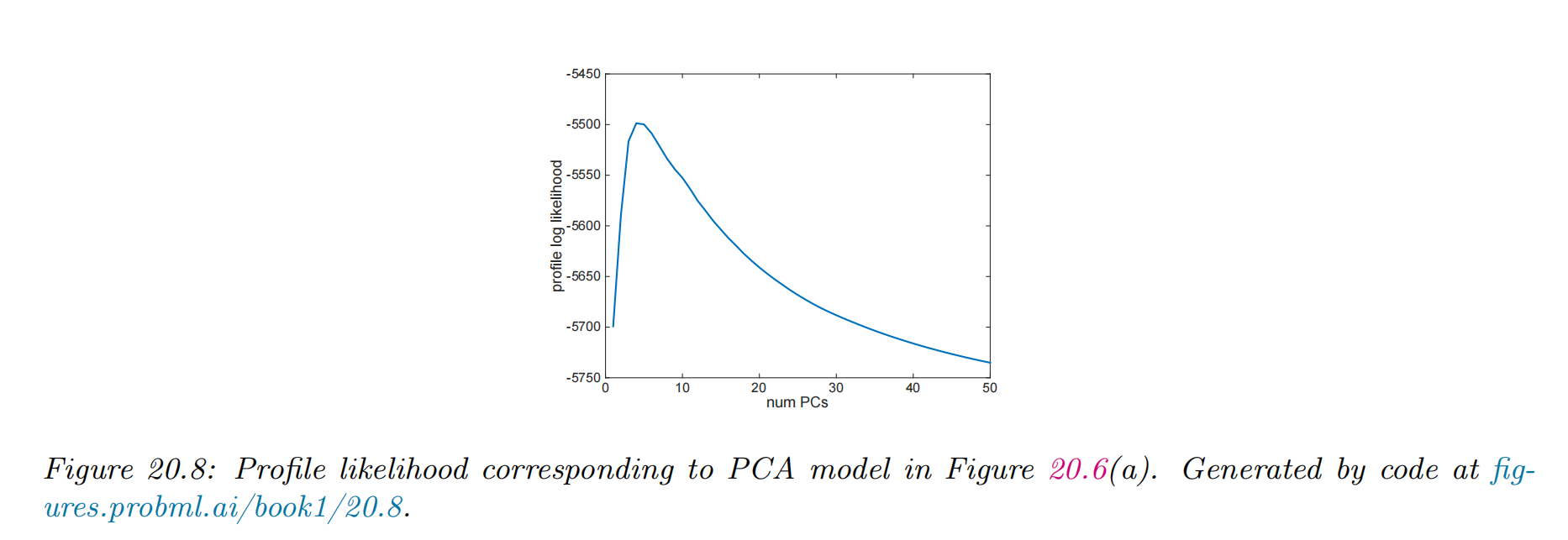
Profile likelihood
μ1(L)μ2(L)σ2(L)=L∑k≤Lλk=Lmax−L∑k>Lλk=Lmax∑k≤L(λk−μ1(L))2+∑k>L(λk−μ2(L))2
We can then evaluate the profile log likelihood ℓ(L)=k=1∑LlogN(λk∣μ1(L),σ2(L))+k=L+1∑LmaxlogN(λk∣μ2(L),σ2(L))
L∗=argmaxℓ(L)
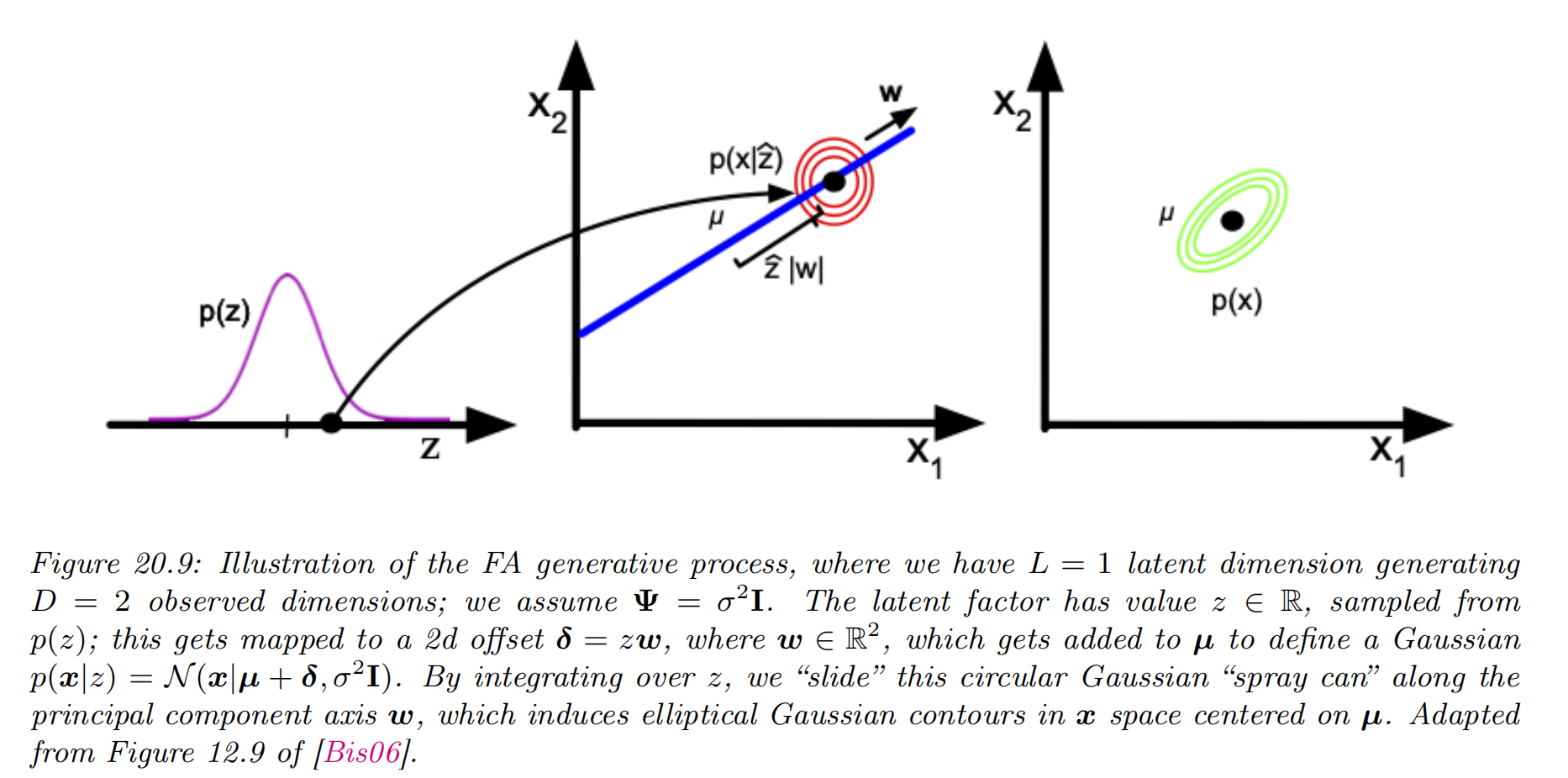
Factor analysis *
Generative model
Factor analysis corresponds to the following linear-Gaussian latent variable generative model: p(z)p(x∣z,θ)=N(z∣μ0,Σ0)=N(x∣Wz+μ,Ψ)
where W is a D×L matrix, known as the factor loading matrix, and Ψ is a diagonal D×D covariance matrix.
FA can be thought of as a low-rank version of a Gaussian distribution. p(x∣θ)=∫N(x∣Wz+μ,Ψ)N(z∣μ0,Σ0)dz=N(x∣Wμ0+μ,Ψ+WΣ0W⊤)
E[x]=Wμ0+μ
Cov[x]=WCov[z]W⊤+Ψ=WΣ0W⊤+Ψ.
a simplification: p(z)p(x∣z)p(x)=N(z∣0,I)=N(x∣Wz+μ,Ψ)=N(x∣μ,WW⊤+Ψ)
In general, FA approximates the covariance matrix of the visible vector using a low-rank decomposition: C=Cov[x]=WW⊤+Ψ
We can estimate the parameters of an FA model using EM.
Probabilistic PCA
a special case
W has orthonormal columns, Ψ=σ2I and μ=0.
This model is called probabilistic principal components analysis (PPCA), or sensible PCA.
The marginal distribution on the visible variables has the form p(x∣θ)=∫N(x∣Wz,σ2I)N(z∣0,I)dz=N(x∣μ,C)
where C=WW⊤+σ2I
The log likelihood for PPCA is given by logp(X∣μ,W,σ2)=−2NDlog(2π)−2Nlog∣C∣−21n=1∑N(xn−μ)⊤C−1(xn−μ)
The MLE for μ is x. Plugging in gives logp(X∣μ,W,σ2)=−2N[Dlog(2π)+log∣C∣+tr(C−1S)]
where S=N1∑n=1N(xn−x)(xn−x)⊤ is the empirical covariance matrix.
In [TB99; Row97] they show that the maximum of this objective must satisfy W=UL(LL−σ2I)21R
where UL is a D×L matrix whose columns are given by the L eigenvectors of S with largest eigenvalues, LL is the L×L diagonal matrix of eigenvalues, and R is an arbitrary L×L orthogonal matrix, which (WLOG) we can take to be R=I. In the noise-free limit, where σ2=0, we see that Wmle =ULLL21, which is proportional to the PCA solution.
The MLE for the observation variance is σ2=D−L1i=L+1∑Dλi
which is the average distortion associated with the discarded dimensions. If L=D, then the estimated noise is 0 , since the model collapses to z=x.
To use PPCA as an alternative to PCA, we need to compute the posterior mean E[z∣x], which is the equivalent of the encoder model. Using Bayes rule for Gaussians we have p(z∣x)=N(z∣M−1W⊤(x−μ),σ2M−1)
where M is defined in Equation (20.48). In the σ2=0 limit, the posterior mean using the MLE parameters becomes E[z∣x]=(W⊤W)−1W⊤(x−x)
which is the orthogonal projection of the data into the latent space, as in standard PCA.
Factor analysis models for paired data
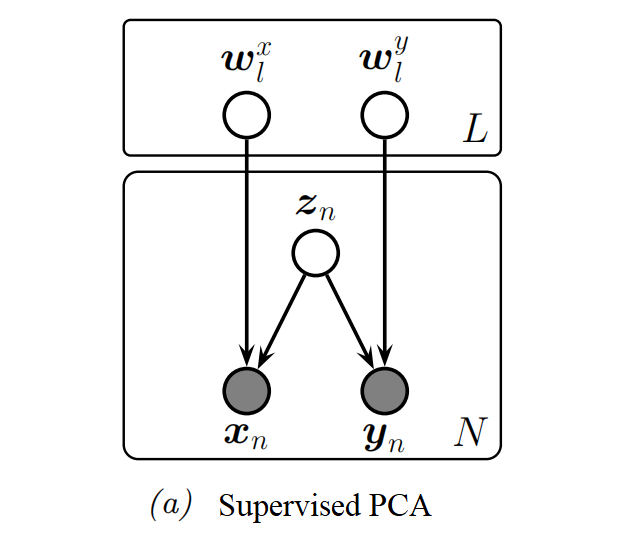
Supervised PCA
model the joint p(x,y) using a shared low-dimensional representation using the following linear Gaussian model: p(zn)p(xn∣zn,θ)p(yn∣zn,θ)=N(zn∣0,IL)=N(xn∣Wxzn,σx2IDx)=N(yn∣Wyzn,σy2IDy)
zn is a shared latent subspace, that captures features that xn and yn have in common.
The variance terms σx and σy control how much emphasis the model puts on the two different signals.
If we put a prior on the parameters θ=(Wx,Wy,σx,σy), we recover the Bayesian factor regression model.
We can marginalize out zn to get p(yn∣xn). If yn is a scalar, this becomes p(yn∣xn,θ)Cv=N(yn∣xn⊤v,wy⊤Cwy+σy2)=(I+σx−2Wx⊤Wx)−1=σx−2WxCwy
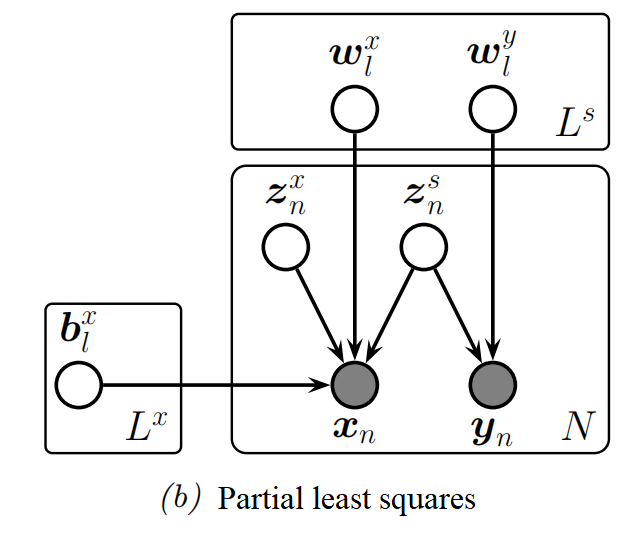
Partial least squares
Another way to improve the predictive performance in supervised tasks is to allow the inputs x to have their own "private" noise source that is independent on the target variable
introducing an extra latent variable znx just for the inputs, that is different from zns that is the shared bottleneck between xn and yn.
In the Gaussian case, the overall model has the form p(zn)p(xn∣zn,θ)p(yn∣zn,θ)=N(zns∣0,I)N(znx∣0,I)=N(xn∣Wxzns+Bxznx,σx2I)=N(yn∣Wyzns,σy2I)
MLE for θ in this model is equivalent to the technique of partial least squares (PLS).
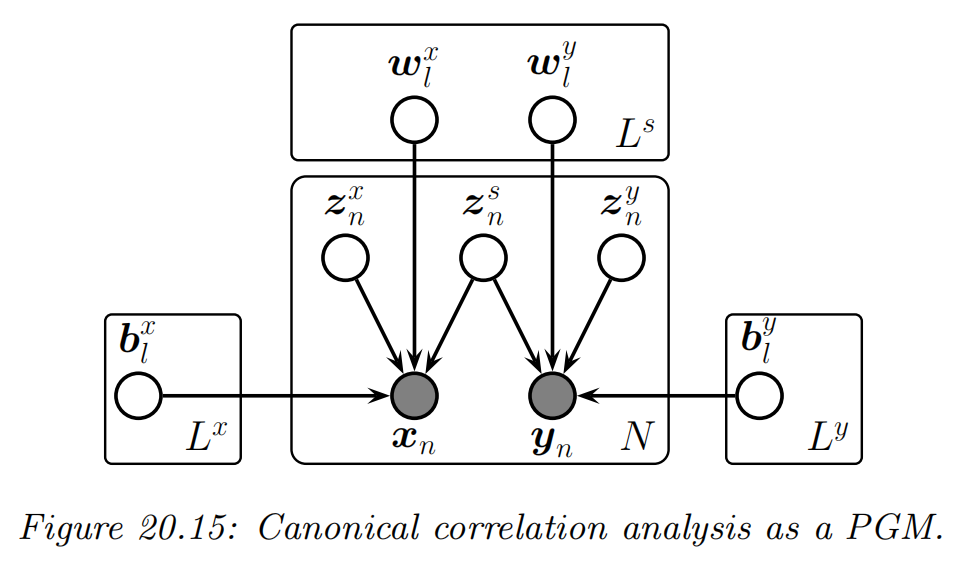
Canonical correlation analysis
use a fully symmetric model:
a latent variable znx just for xn
a latent variable zny just for yn
a shared latent variable zns
the Gaussian case: p(zn)p(xn∣zn,θ)p(yn∣zn,θ)=N(zns∣0,I)N(znx∣0,I)=N(xn∣Wxzns+Bxznx,σx2I)=N(yn∣Wyzns+Byzny,σy2I)
where Wx and Wy are Ls×D dimensional, Vx is Lx×D dimensional, and Vy is Ly×D dimensional.
marginalizing out all the latent variables (where we assume σx=σy=σ ): p(xn,yn)=∫dznp(zn)p(xn,yn∣zn)=N(xn,yn∣μ,WW⊤+σ2I)
where μ=(μx;μy), and W=[Wx;Wy].
Thus the induced covariance is the following low rank matrix: WW⊤=(WxWx⊤WyWy⊤WxWy⊤WyWy⊤)
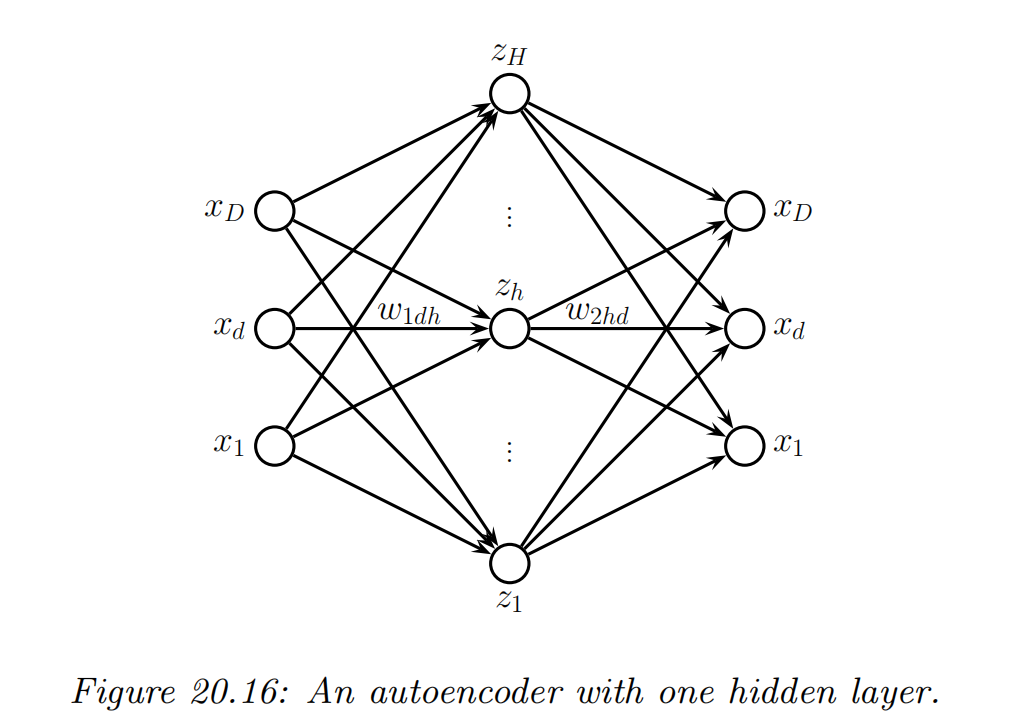
Autoencoders
recall what we learned from PCA
Encoder:fe:x→z
Decoder:fd:z→x
The overall reconstruction function:r(x)=fd(fe(x))
loss function:L(θ)=∥r(x)−x∥22 or L(θ)=−logp(x∣r(x))
Autoencoder: the encoder and decoder are nonlinear mappings implemented by neural networks.
Bottleneck: the hidden units in the middle (as a low-dimensional bottleneck) between the input and its reconstruction.