by writing x as [1,x1,x2,…,xD], we can write w as [w0,w1,…,wD]
simple linear regression
D=1
f(x;w)=ax+b
multiple linear regression
x∈RD,D>1
multivariate linear regression
x∈RD,D>1
y∈RJ,J>1 p(y∣x,W)=j=1∏JN(yj∣wjTx,σj2)
if y can not be well fitted by linear function of x
apply nonlinear transformation ϕ (feature extractor) to x
as long as the parameters for ϕ are fixed, the model remains linear in parameters p(y∣x,θ)=N(y∣wTϕ(x),σ2)
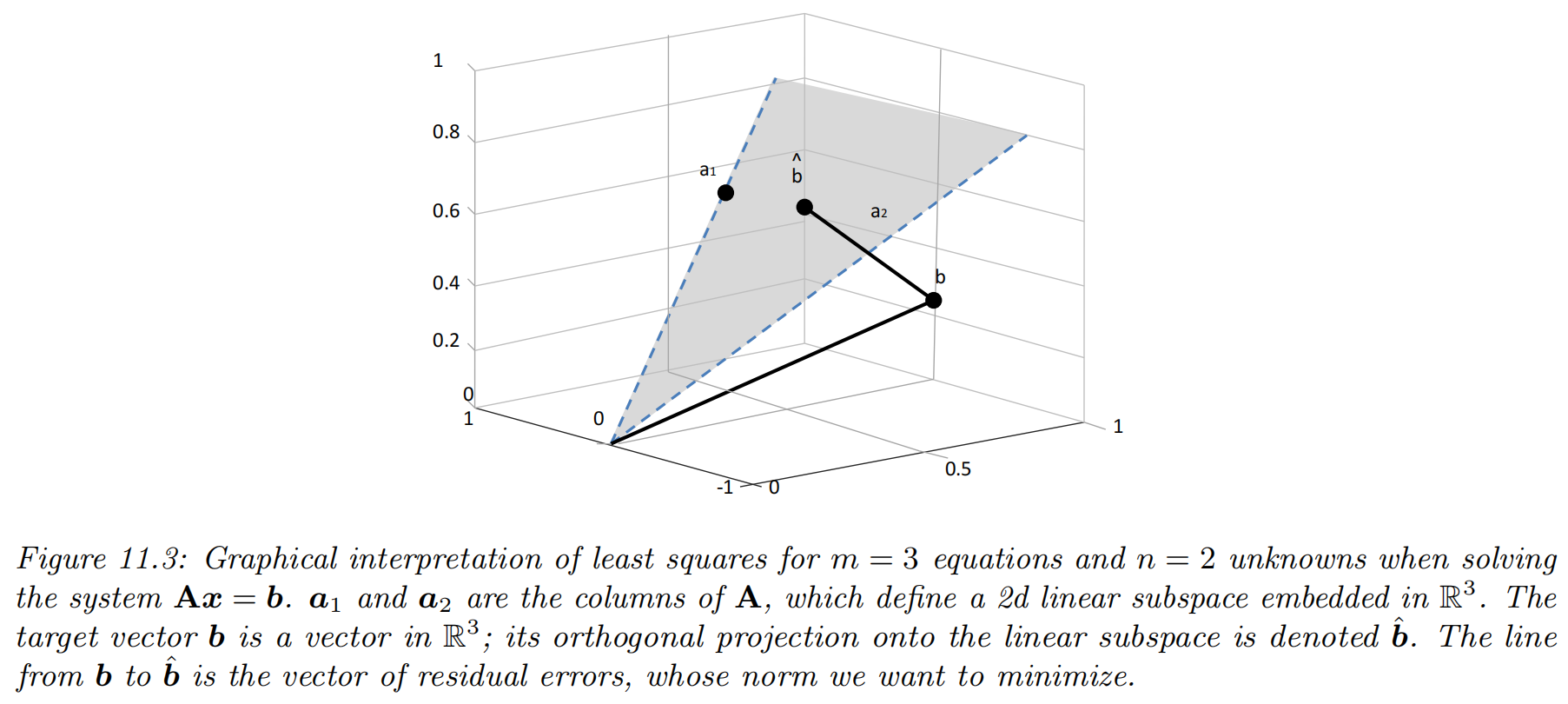
Least squares estimation
minimizing the negative log likelihood (NLL): NLL(w,σ2)==−∑n=1Nlog[(2πσ21)21exp(−2σ21(yn−wTxn)2)]2πσ21∑n=1N(y−y^)2+2Nlog(2πσ2)
y^n=wTx
The MLE is the point where: ∇w,σNLL(w,σ2)=0
the NLL is equal to the residual sum of squares (RSS) RSS(w)=21n=1∑N(yn−wTxn)2=21∥Xw−y∥22=21(Xw−y)T(Xw−y)
OLS
∇wRSS(w)=XTXw−XTy
the normal equation (FOC) XTXw=XTy the OLS solution w^=(XTX)−1XTy
the solution is unique since tha Hessian is positive definite H(w)=∂w2∂2RSS(w)=XTX
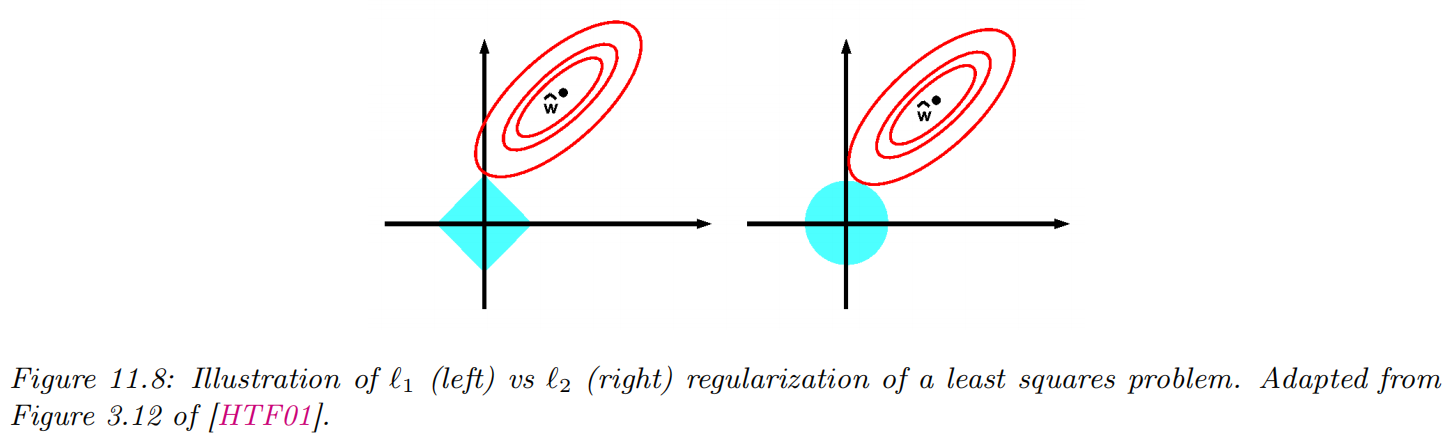
ridge regression: MAP estimation with a zero-mean Gaussian prior on the weights p(w)=N(w∣0,λ−1I)
MAP estimate w^map =argmin2σ21(y−Xw)⊤(y−Xw)+2τ21w⊤w=argminRSS(w)+λ∥w∥22
where λ≜τ2σ2 is proportional to the strength of the prior, and ∥w∥2≜d=1∑D∣wd∣2=w⊤w
l2 regularization or weight decay
Choosing the strength of the regularizer
the simple (but expensive) idea
try a finite number of distinct values
use cross validation to estimate their expected loss
a practitical method
start with a highly constrained model (strong regularizer)
gradually relax the constraints (decrease the amount of regularization)
empirical Bayes approach: λ^=argmaxλlogp(D∣λ)
get the same result as the CV estimate
can be done by fitting a single model
use gradient-based optimization instead of discrete search
Lasso regression
least absolute shrinkage and selection operator(LASSO) PNLL(w)=−logp(D∣w)−logp(w∣λ)=∥Xw−y∥22+λ∥w∥1
l1-regularization: MAP estimation with a Laplace prior Lap(w∣μ,b)≜2b1exp(−b∣w−μ∣)
other norms
in general: ∥w∥q=(∑d=1D∣wd∣q)1/q
q<1
even sparser solutions
the problem becomes non-convex
q=0 (l0−norm): ∥w∥0=∑d=1DI(∣wd∣>0)
Why does l1 regularization yield sparse solutions?
lasso/ridge as Lagrangian of constrained optimization problem
lasso: wminNNL(w)+λ∥w∥1≤B
ridge: wminNNL(w)+λ∥w∥22≤B
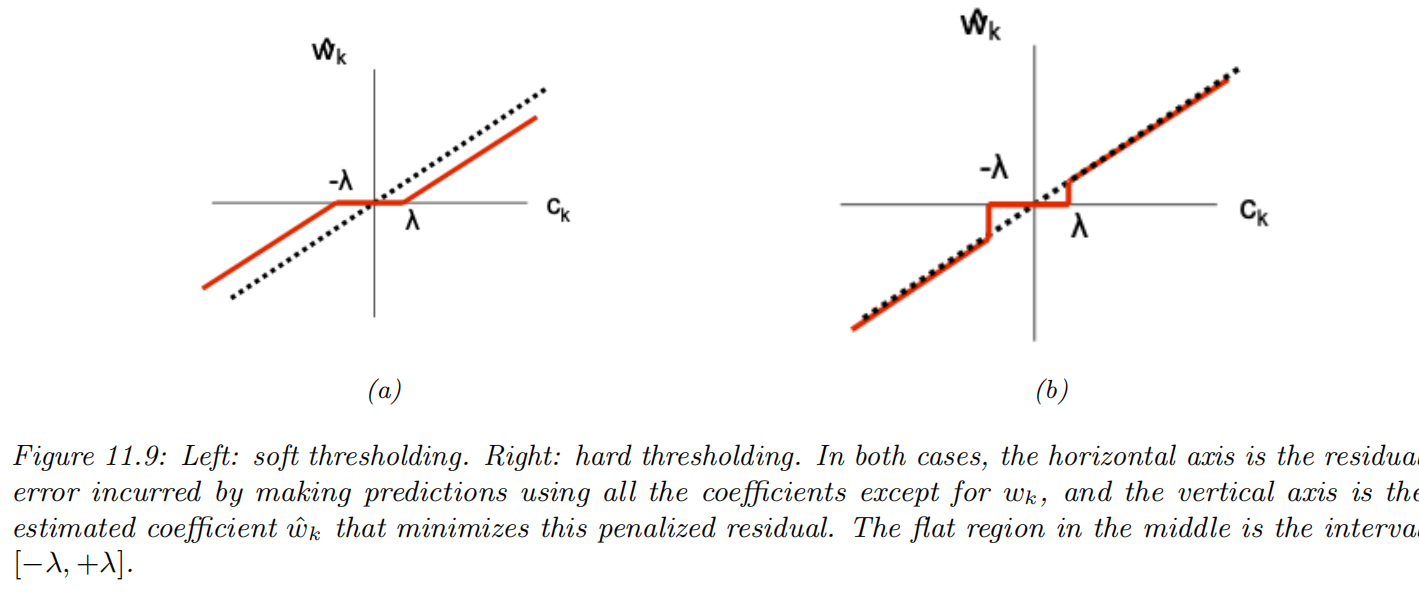
Hard vs soft thresholding
Consider the partial derivatives of the lasso objective
adding the l1 part ∂wdL(w)=(adwd−cd)+λ∂wd∥w∥1=⎩⎨⎧{adwd−cd−λ}[−cd−λ,−cd+λ]{adwd−cd+λ} if wd<0 if wd=0 if wd>0
the solution
If cd<−λ, so the feature is strongly negatively correlated with the residual, then the subgradient is zero at w^d=adcd+λ<0.
If cd∈[−λ,λ], so the feature is only weakly correlated with the residual, then the subgradient is zero at w^d=0.
If cd>λ, so the feature is strongly positively correlated with the residual, then the subgradient is zero at w^d=adcd−λ>0. w^d(cd)=⎩⎨⎧(cd+λ)/ad0(cd−λ)/ad if cd<−λ if cd∈[−λ,λ] if cd>λ
We can write this as w^d=SoftThreshold(adcd,λ/ad)
SoftThreshold(x,δ)≜sign(x)(∣x∣−δ)+
hard thresholding:
wd=0 for −λ≤cd≤λ
does not shrink the values of wd for other cases
debiasing: the two-stage estimation process
run lasso to get the sparse estimaion
run ols with the variable from lasso
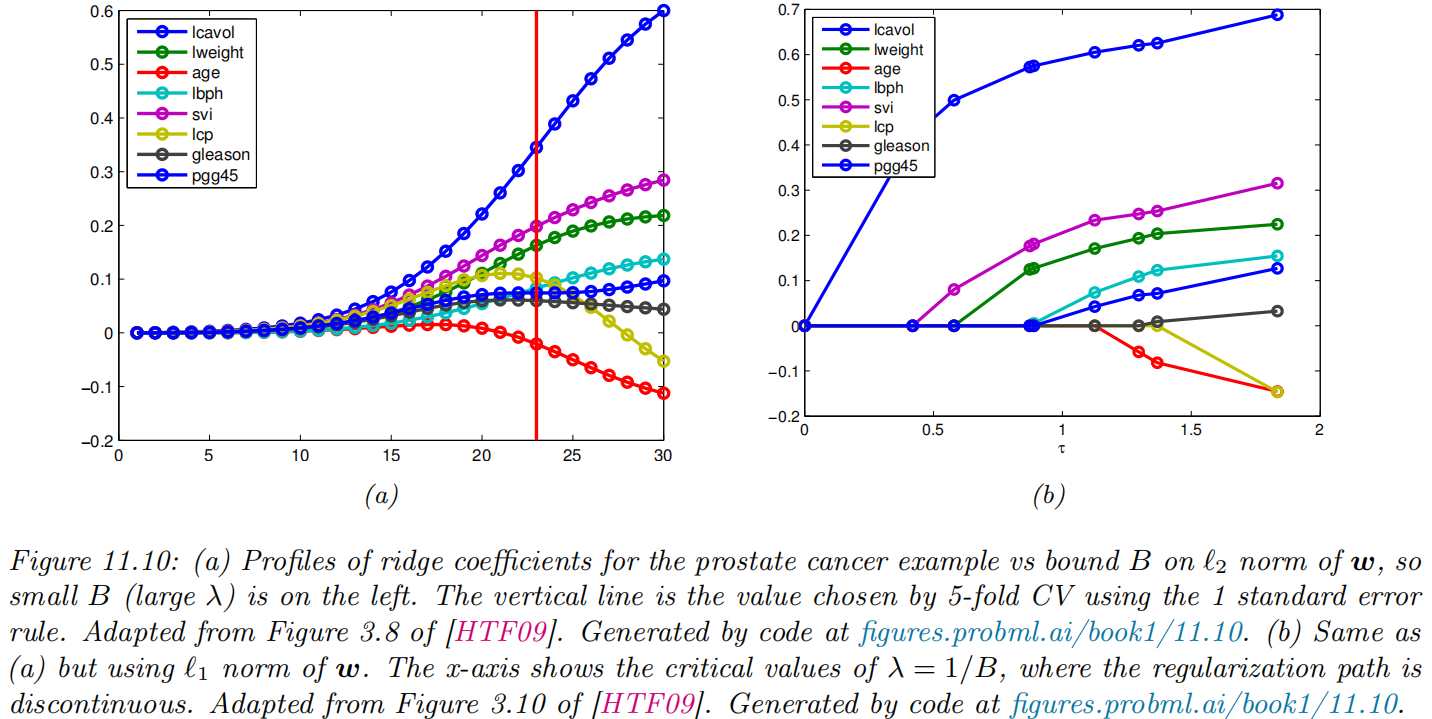
Regularization path
Plot the values w^d vs λ (or vs the bound B) for each feature d.
Group lasso
group sparsity
many parameters associated with a given variable
a vector of weights wd for variable d
If we want to exclude variable d, we have to force the whole subvector wd to go to zero
applications
Linear regression with categorical inputs: If the d’th variable is categorical with K possible levels, then it will be represented as a one-hot vector of length K, so to exclude variable d, we have to set the whole vector of incoming weights to 0.
Multinomial logistic regression: The d’th variable will be associated with C different weights, one per class, so to exclude variable d, we have to set the whole vector of outgoing weights to 0.
Neural networks: the k’th neuron will have multiple inputs, so if we want to “turn the neuron off”, we have to set all the incoming weights to zero. This allows us to use group sparsity to learn neural network structure.
Multi-task learning: each input feature is associated with C different weights, one per output task. If we want to use a feature for all of the tasks or none of the tasks, we should select weights at the group level.