L01 Introduction of Machine Learning
Materials are adopted from "Murphy, Kevin P. Probabilistic machine learning: an introduction. MIT press, 2022.". This handout is only for teaching. DO NOT DISTRIBUTE.
What is ML
-
Definition of ML
A computer program is said to learn from experience with respect to some class of tasks , and performance measure , if its performance at tasks in , as measured by , improves with experience .
--Tom Mitchell
-
The probabilistic approach
- treat all unknown quantities as random variables
- it is the optimal approach to decision making under uncertainty
Almost all of machine learning can be viewed in probabilistic terms, making probabilistic thinking fundamental. It is, of course, not the only view. But it is through this view that we can connect what we do in machine learning to every other computational science, whether that be in stochastic optimisation, control theory, operations research, econometrics, information theory, statistical physics or bio-statistics. For this reason alone, mastery of probabilistic thinking is essential.
---Shakir Mohamed, DeepMind
-
Machine Learning vs. Statistic Approaches
- Statistical approaches rely on foundational assumptions and explicit models of structure, such as observed samples that are assumed to be drawn from a specified underlying probability distribution.
- Machine learning seeks to extract knowledge from large amounts of data with no such restrictions -- “find the pattern, apply the pattern.”
-
Supervised Learning vs. Unsupervised Learning
- Supervised learning involves ML algorithms that infer patterns between a set of inputs (the ’s) and the desired output () with a labeled data set.
- Unsupervised learning is machine learning that does not make use of labeled data. In unsupervised learning, inputs (’s) are used for analysis without any target () being supplied. The algorithm seeks to discover structure within the data themselves. Two important types of problems in unsupervised learning are dimension reduction and clustering.
-
Deep Learning and Reinforcement Learning
- In deep learning, sophisticated algorithms address highly complex tasks, such as image classification, face recognition, speech recognition, and natural language processing.
- reinforcement learning, a computer learns from interacting with itself (or data generated by the same algorithm).
- Neural networks (NNs, also called artificial neural networks, or ANNs) include highly flexible ML algorithms that have been successfully applied to a variety of tasks characterized by non-linearities and interactions among features.
- Besides being commonly used for classification and regression, neural networks are also the foundation for deep learning and reinforcement learning, which can be either supervised or unsupervised.
Supervised Learning
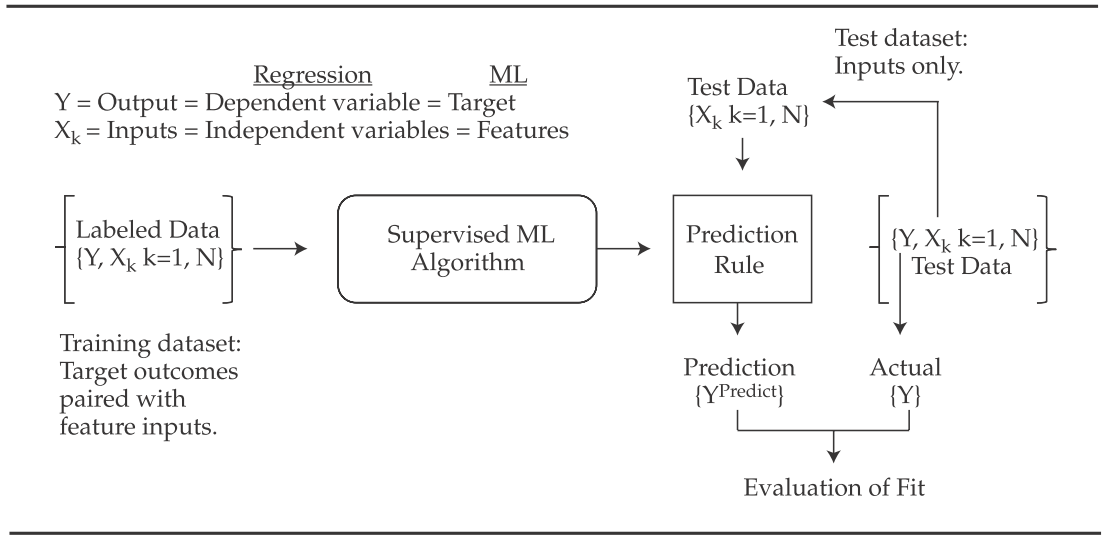
- Definition
- The task is to learn a mapping from inputs to outputs
- The inputs are also called the features, covariates, or predictors
- The outputs are also called the label, target, or response
- The experince is the training set
Classification
classification problem
- the output space is a set of unordered and mutually exclusive labels known as classes, .
- The problem is also called pattern recognition.
- binary classification: just two classes, often denoted by
Example: classifying Iris flowers
Iris Flowers Classification

Image Classification

Exploratory data analysis
- exploratory data analysis: see if there are any obvious patterns
- tabular data with a small number of features: pair plot
- higher-dimensional data: dimension reduction first and then to visualize the data in 2d or 3d

Learning a classifier
-
decision rule via a 1 dimensional (1d) decision boundary
-
decision tree a more sophisticated decision rule involves a 2d decision surface
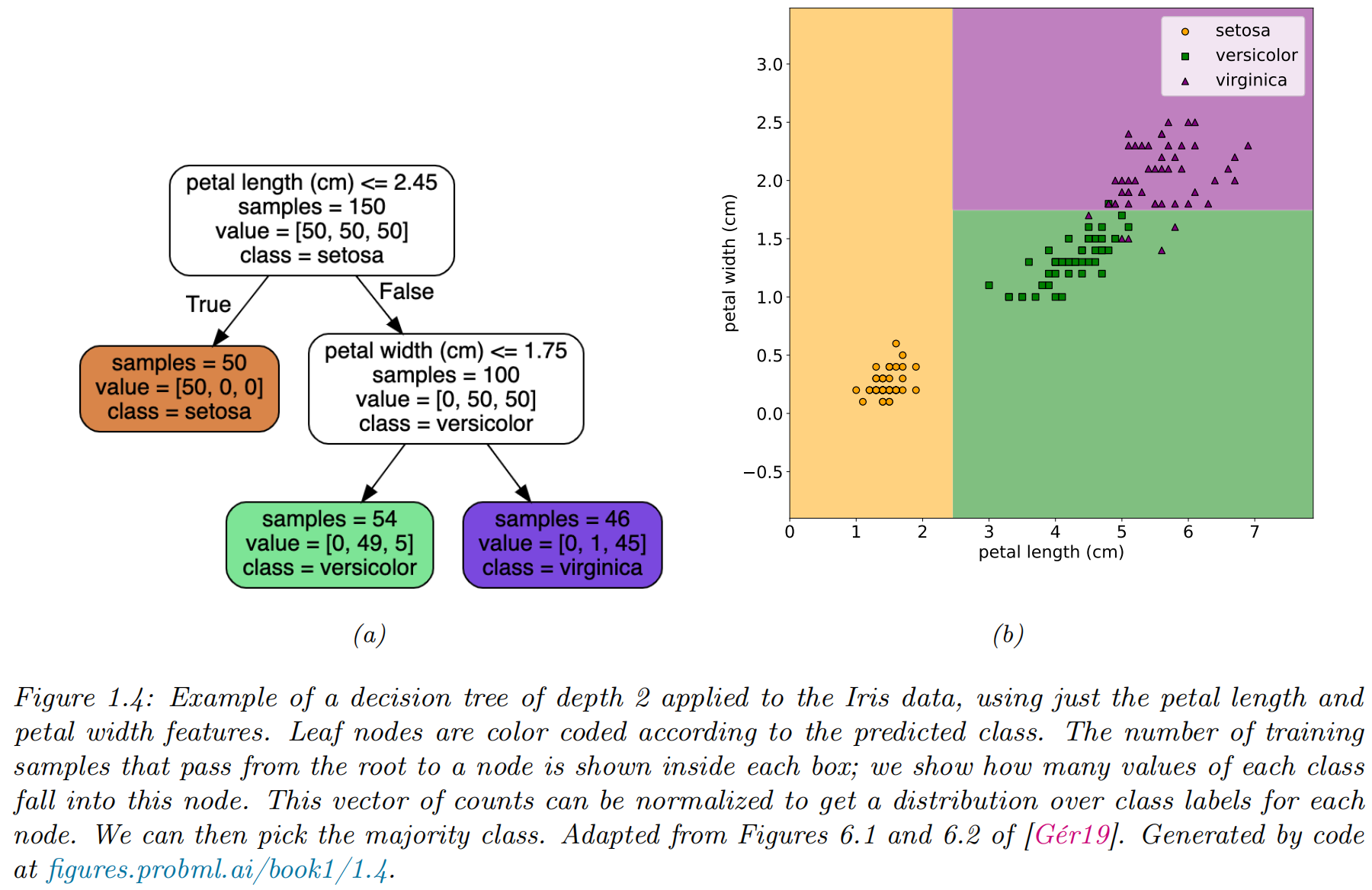
Empirical risk minimization
- misclassification rate on the training set:
- loss function:
- empirical risk: e the average loss of the predictor on the training set
- model fitting / training via empirical risk minimization
Uncertainty
We must avoid] false confidence bred from an ignorance of the probabilistic nature of the world, from a desire to see black and white where we should rightly see gray.
--- Immanuel Kant, as paraphrased by Maria Konnikova
- Two types of uncertainties
- epistemic uncertainty or model uncertainty: due to
lack of knowledge of the input-output mapping - aleatoric uncertainty or data uncertainty: due to intrinsic (irreducible) stochasticity in the mapping
- epistemic uncertainty or model uncertainty: due to
- We can capture our uncertainty using the following conditional probability distribution:
Maximum likelihood estimation
-
likelihood function:
-
log likelihood function
-
Negative Log Likelihood: The average negative probability of the training set.
-
the maximum likelihood estimate (MLE):
Regression
regression problem
- the output space: .
- loss function: quadratic loss, or loss:
- mean squared error or MSE:
- An Example
- Uncertainty: Guassian / Normal
- the conditional dist
- NLL
- Uncertainty: Guassian / Normal
(simple) Linear regression
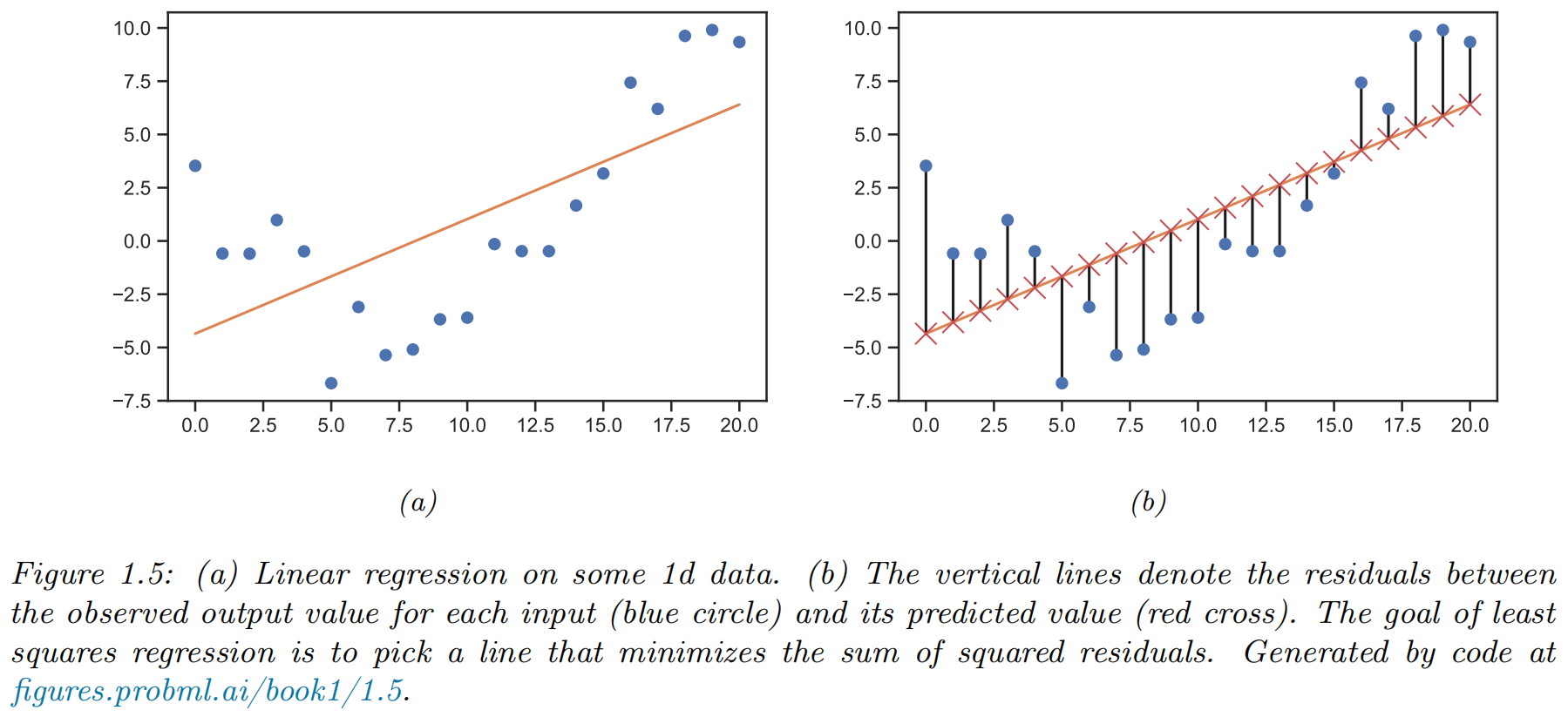
- functional form of model:
- parameters:
- least square estimator:
Polynomial regression
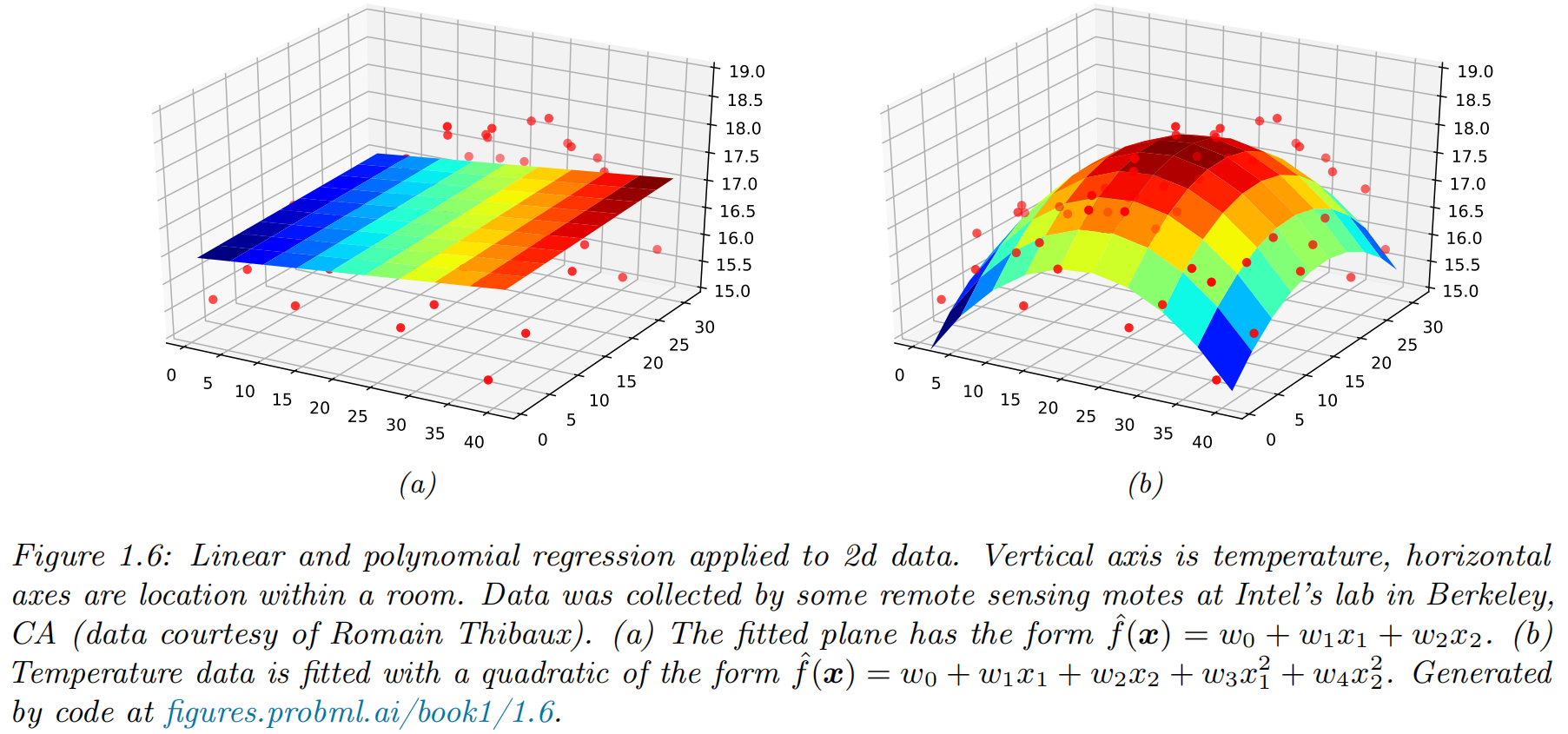
- functional form of model:
- feature preprocessing, or feature engineering
Deep neural networks
- deep neural networks (DNN): a stack of L nested functions:
- the function at layer :
- the final layer:
- the learned feature extractor:
- the final layer:
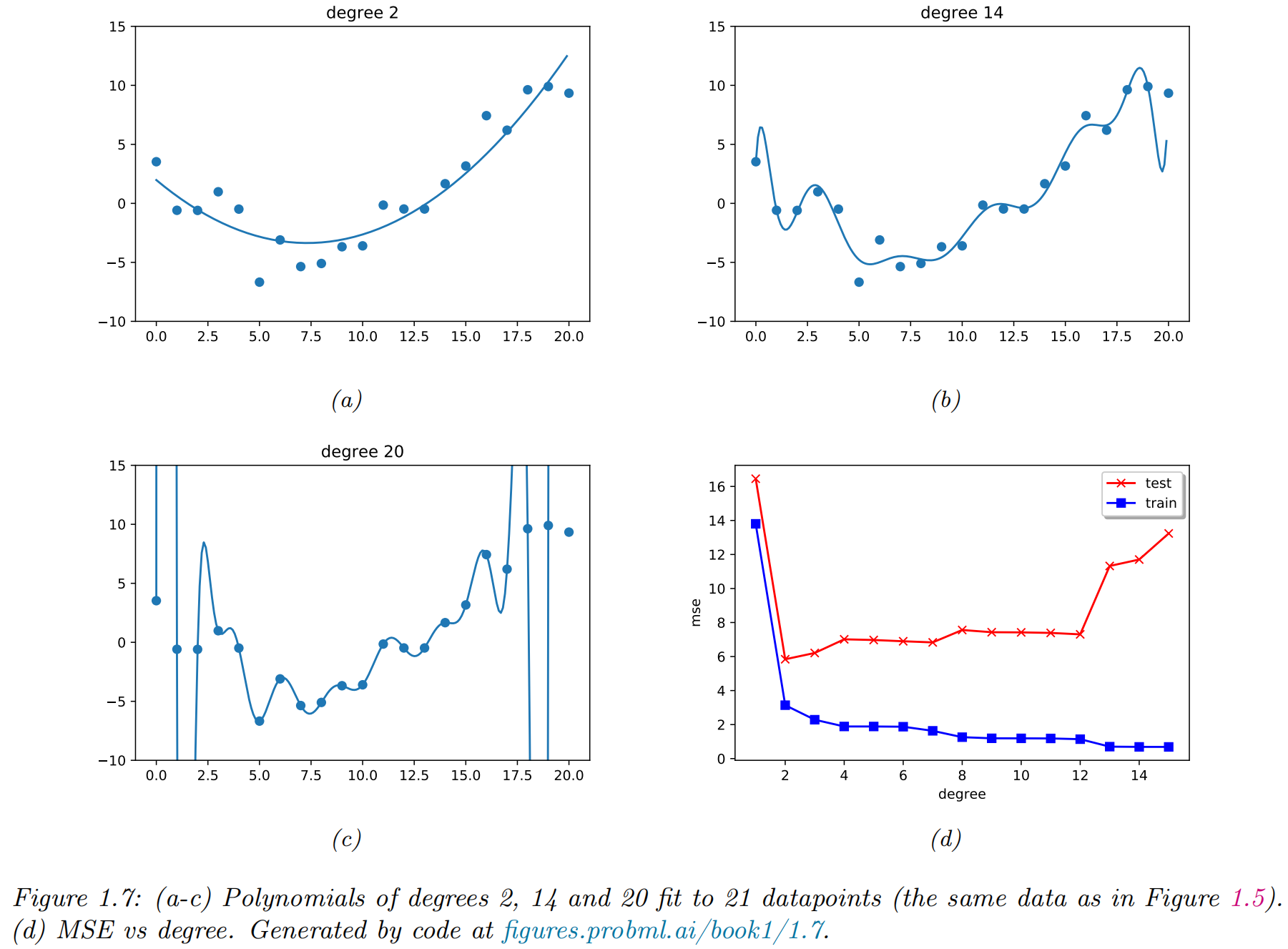
Overfitting and generalization
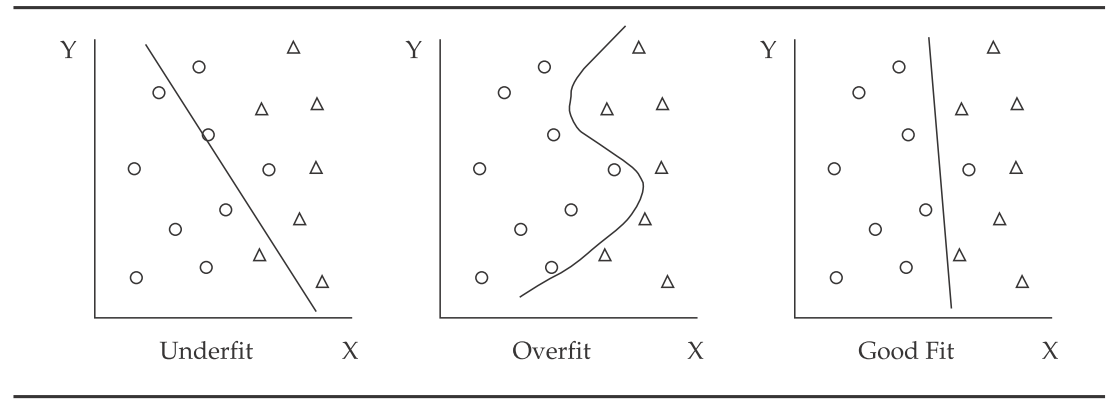
-
Underfitting means the model does not capture the relationships in the data.
-
Overfitting means the model begins to incorporate noise coming from quirks or spurious correlations
- it mistakes randomness for patterns and relationships
- memorized the data, rather than learned from it
- high noise levels in the data and too much complexity in the model
- complexity refers to the number of features, terms, or branches in the model and to whether the model is linear or non-linear (non-linear is more complex).
-
empirical risk
-
population risk
-
generalization gap:
-
test risk
Evaluating ML Algorithm Performance Errors & Overfitting
- Data scientists decompose the total out-of-sample error into three sources:
- Bias error, or the degree to which a model fits the training data. Algorithms with erroneous assumptions produce high bias with poor approximation, causing underfitting and high in-sample error.
- Variance error, or how much the model's results change in response to new data from validation and test samples. Unstable models pick up noise and produce high variance, causing overfitting
- Base error due to randomness in the data.
learning curve
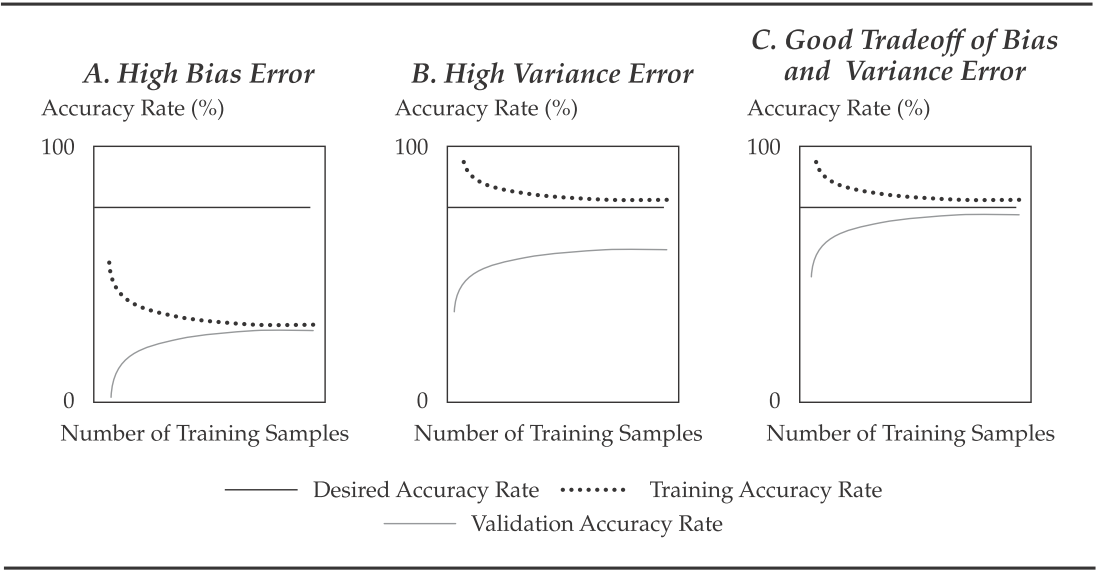
- A learning curve plots the accuracy rate (= 1 – error rate) in the validation or test samples (i.e., out-of-sample) against the amount of data in the training sample
fitting curve

- A fitting curve, which shows in-and out-of-sample error rates ( and ) on the -axis plotted against model complexity on the -axis
Evaluating ML Algorithm Performance: Preventing Overfitting in Supervised ML
-
Two common guiding principles and two methods are used to reduce overfitting:
- preventing the algorithm from getting too complex during selection and training (regularization)
- proper data sampling achieved by using cross-validation
-
K-fold cross-validation
- data (excluding test sample and fresh data) are shuffled randomly and then are divided into k equal sub-samples
- samples used as training samples and one sample used as a validation sample
- is typically set at 5 or 10
- This process is repeated times. The average of the validation errors (mean ) is taken as a reasonable estimate of the model's out-of-sample error ()
-
Leave-one-out cross-validation:
No free lunch theorem
All models are wrong, but some models are useful.
--- George Box
- No free lunch theorem: There is no single best model that works optimally for all kinds of problems
- pick a suitable model
- based on domain knowledge
- trial and error
- cross-validation
- Bayesian methods selection techniques
Unsupervised learning
- unsupervised learning: “inputs” without any corresponding “outputs” .
- the task: fitting an unconditional model of the form
When we’re learning to see, nobody’s telling us what the right answers are — we just look. Every so often, your mother says “that’s a dog”, but that’s very little information. You’d be lucky if you got a few bits of information — even one bit per second — that way. The brain’s visual system has 1014 neural connections. And you only live for 109 seconds. So it’s no use learning one bit per second. You need more like 105 bits per second. And there’s only one place you can get that much information: from the input itself.
--- Geoffrey Hinton, 1996
Clustering
- finding clusters in data: partition the input into regions that contain “similar” points.
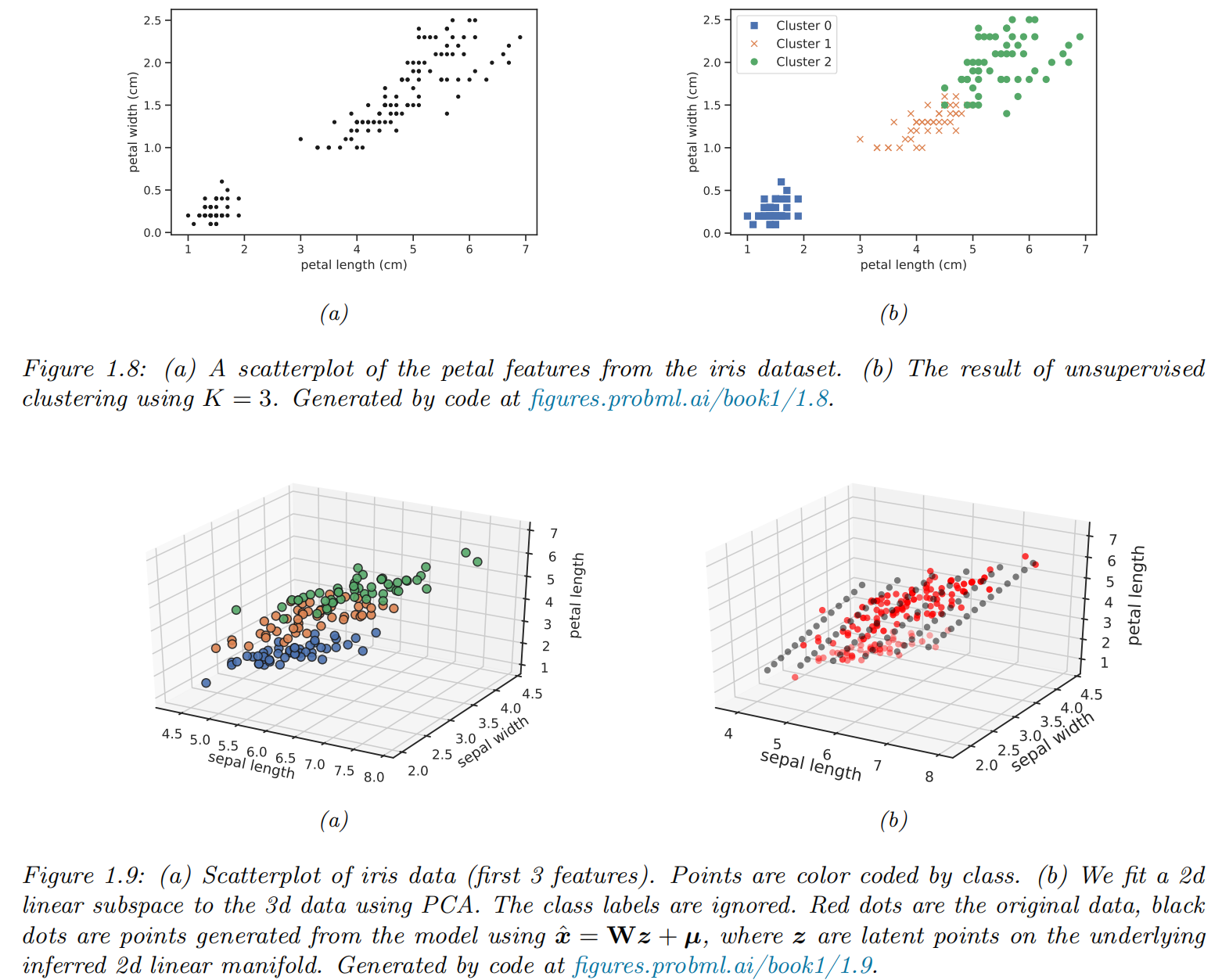
Discovering latent “factors of variation”
-
Assume that each observed high-dimensional output was generated by a set of hidden or unobserved low-dimensional latent factors .
-
factor analysis (FA)
-
principal components analysis (PCA):
-
nonlinear models: neural networks
Reinforcement learning

- online / dynamic version of machine learning
- the system or agent has to learn how to interact
with its environment - RL is closely related to the Markov Decision Process (MDP)
- the system or agent has to learn how to interact
Markov Decision Process
The MDP is the sequence of random variables () which describes the stochastic evolution of the system states. Of course the distribution of () depends on the chosen actions.
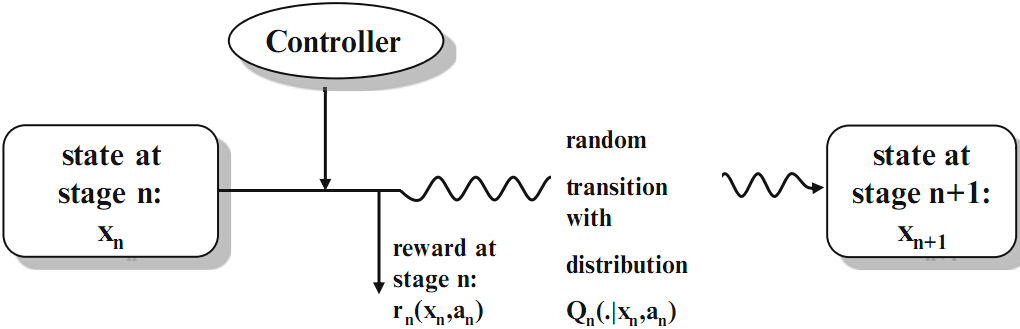
-
denotes the state space of the system. A state is the information which is available for the controller at time . Given this information an action has to be selected.
-
denotes the action space. Given a specific state at time , a certain subclass of actions may only be admissible.
-
is a stochastic transition kernel which gives the probability that the next state at time is in the set B if the current state is and action a is taken at time .
-
gives the (discounted) one-stage reward of the system at time if the current state is and action a is taken
-
gives the (discounted) terminal reward of the system at the end of the planning horizon.
A control is a sequence of decision rules () with where determines for each possible state the next action at time . Such a sequence is called policy or strategy. Formally the Markov Decision Problem is given by
-
Types of MDP problems:
- finite horizon () vs. infinite horizon ()
- complete state observation vs. partial state observation
- problems with constraints vs. without constraints
- total (discounted) cost criterion vs. average cost criterion
-
Research questions:
- Does an optimal policy exist?
- Has it a particular form?
- Can an optimal policy be computed efficiently?
- Is it possible to derive properties of the optimal value function analytically?
Applications of MDP: Comsumption Problem
Suppose there is an investor with given initial capital. At the beginning of each of periods she can decide how much of the capital she consumes and how much she invests into a risky asset. The amount she consumes is evaluated by a utility function as well as the terminal wealth. The remaining capital is invested into a risky asset where we assume that the investor is small and thus not able to influence the asset price and the asset is liquid. How should she consume/invest in order to maximize the sum of her expected discounted utility?
Applications of MDP: Cash Balance or Inventory Problem
Imagine a company which tries to find the optimal level of cash over a finite number of periods. We assume that there is a random stochastic change in the cash reserve each period (due to withdrawal or earnings). Since the firm does not earn interest from the cash position, there are holding cost for the cash reserve if it is positive, but also interest (cost) in case it is negative. The cash reserve can be increased or decreased by the management at each decision epoch which implies transfer costs. What is the optimal cash balance policy?
Applications of MDP: Mean-Variance Problem
Consider a small investor who acts on a given financial market. Her aim is to choose among all portfolios which yield at least a certain expected return (benchmark) after periods, the one with smallest portfolio variance. What is the optimal investment strategy?
Applications of MDP: Dividend Problem in Risk Theory
Imagine we consider the risk reserve of an insurance company which earns some premia on the one hand but has to pay out possible claims on the other hand. At the beginning of each period the insurer can decide upon paying a dividend. A dividend can only be paid when the risk reserve at that time point is positive. Once the risk reserve got negative we say that the company is ruined and has to stop its business. Which dividend pay-out policy maximizes the expected discounted dividends until ruin?
Applications of MDP: Bandit Problem
Suppose we have two slot machines with unknown success probability and . At each stage we have to choose one of the arms. We receive one Euro if the arm wins, else no cash flow appears. How should we play in order to maximize our expected total reward over trials?
Applications of MDP: Pricing of American Options
In order to find the fair price of an American option and its optimal exercise time, one has to solve an optimal stopping problem. In contrast to a European option the buyer of an American option can choose to exercise any time up to and including the expiration time. Such an optimal stopping problem can be solved in the framework of Markov Decision Processes.
Discussion
Statistical inference vs. Supervised machine learning
| Property | Statistical inference | Supervised machine learning |
|---|---|---|
| Goal | Causal models with explanatory power | Prediction performance, often with limited explanatory power |
| Data | The data is generated by a model | The data generation process is unknown |
| Framework | Probabilistic | Algorithmic and Probabilistic |
| Expressibility | Typically linear | Non-linear |
| Model selection | Based on information criteria | Numerical optimization |
| Scalability | Limited to lower-dimensional data | Scales to high-dimensional input data |
| Robustness | Prone to over-fitting | Designed for out-of-sample performance |
| Diagnostics | Extensive | Limited |
Financial Econometrics and Machine Learning

ML Algorithm Types
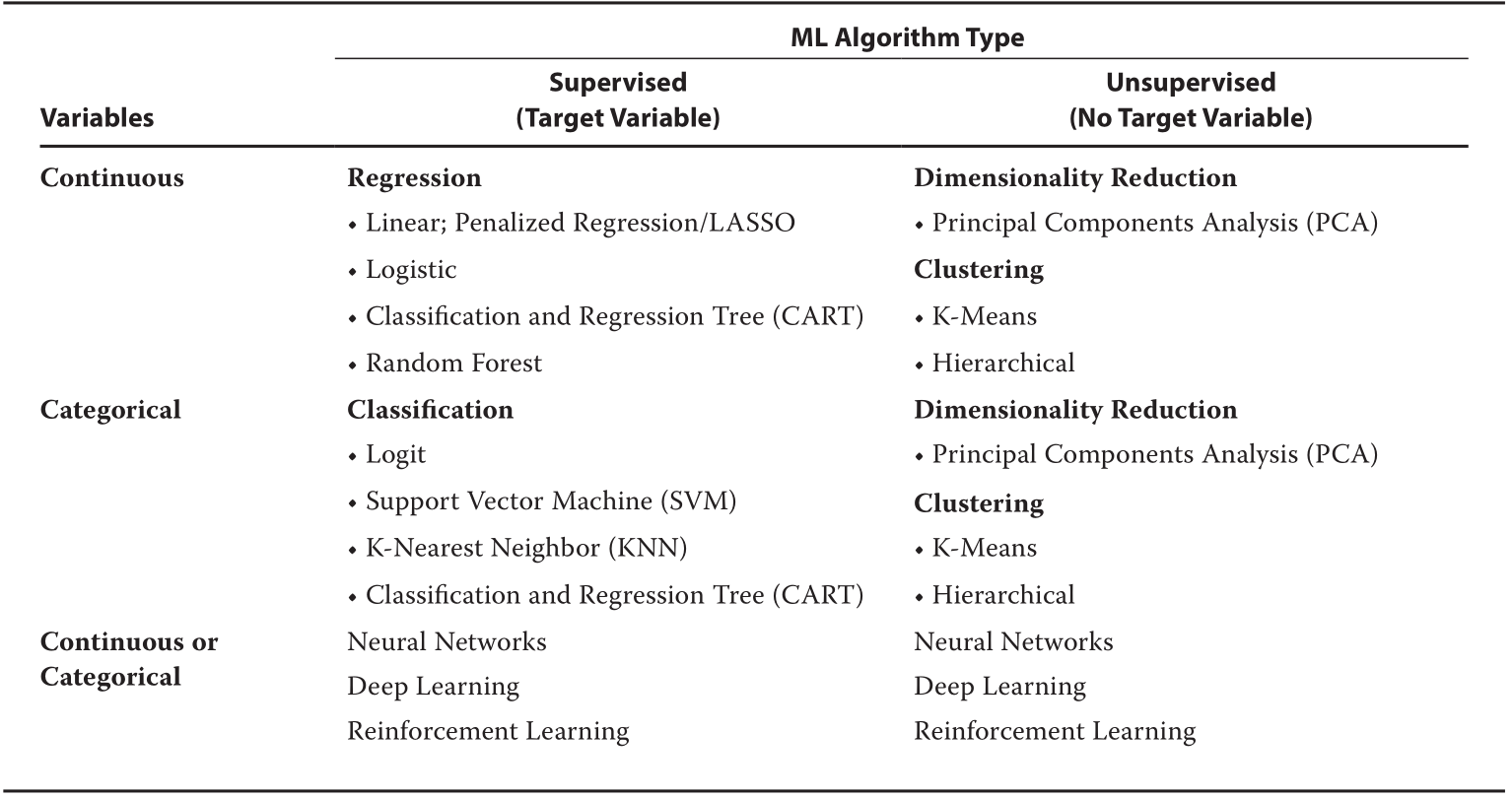
Selecting ML Algorithms
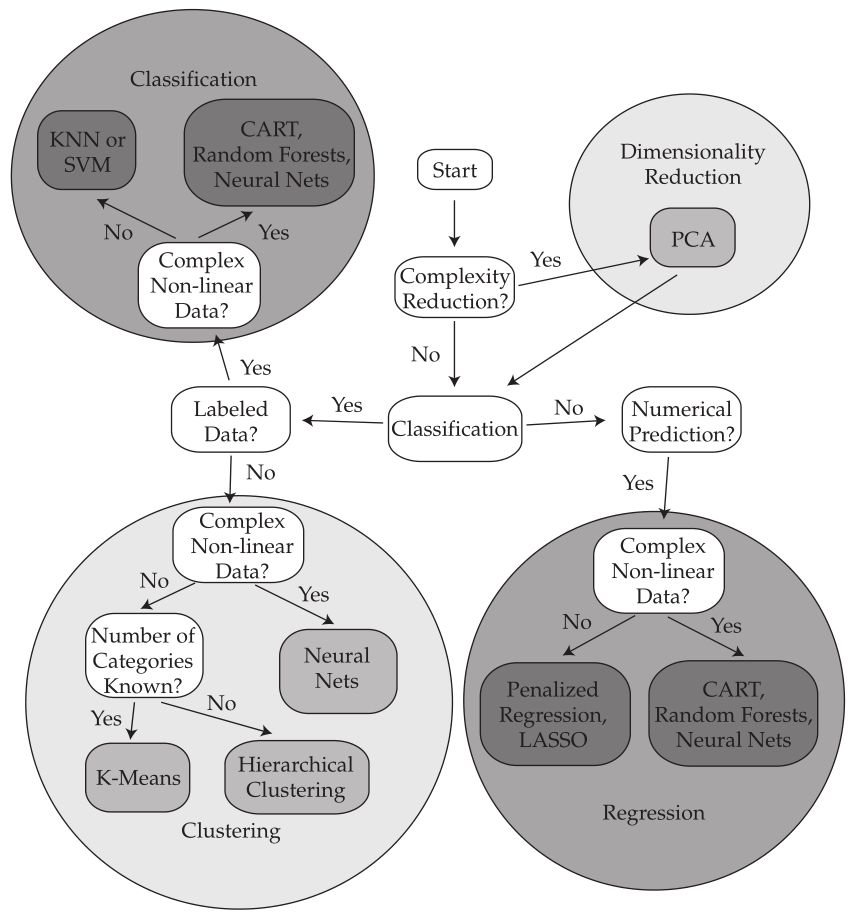
Useful Python Libraries
Popular Data Science Libraries in Python
Math Libraries



Statistical Libraries

ML and Deep Learning




Decision Theory
Bayesian decision theory
Basics
The decision maker, or agent, has a set of possible actions, , to choose from. Each of these actions has costs and benefits, which will depend on the underlying state of nature . We can encode this information into a loss function , that specifies the loss we incur if we take action when the state of nature is .
- The posterior expected loss or risk for each possible action:
- The optimal policy (also called the Bayes estimator) specifies what action to take for each possible observation so as to minimize the risk:
- Let be the utility function, then the optimal policy is as follows (maximum expected utility principle):
Classification problems
We use Bayesian decision theory to decide the optimal class label to predict given an observed input .
Zero-one loss
Suppose the states of nature correspond to class labels, so . Furthermore, suppose the actions also correspond to class labels, so . In this setting, a very commonly used
- the zero-one loss , defined as follows:
- the posterior expected loss
- the optimal policy
It corresponds to the mode of the posterior distribution, also known as the maximum a posteriori or MAP estimate
ROC curves
Class confusion matrices
For any fixed threshold , we consider the following decision rule:
- The empirical number of false positives (FP) that arise from using this policy on a set of N labeled examples:
-
The empirical number of false negatives (FN)
-
The empirical number of true positives (TP)
-
The empirical number of true negatives (TN)
-
class confusion matrix : is the number of times an item with true class label was (mis)classified as having label .

- the true positive rate (TPR), also known as the sensitivity, recall or hit rate
- the false positive rate (FPR), also called the false alarm rate, or the type I error rate
- We can now plot the TPR vs FPR as an implicit function of . This is called a receiver operating characteristic or ROC curve.
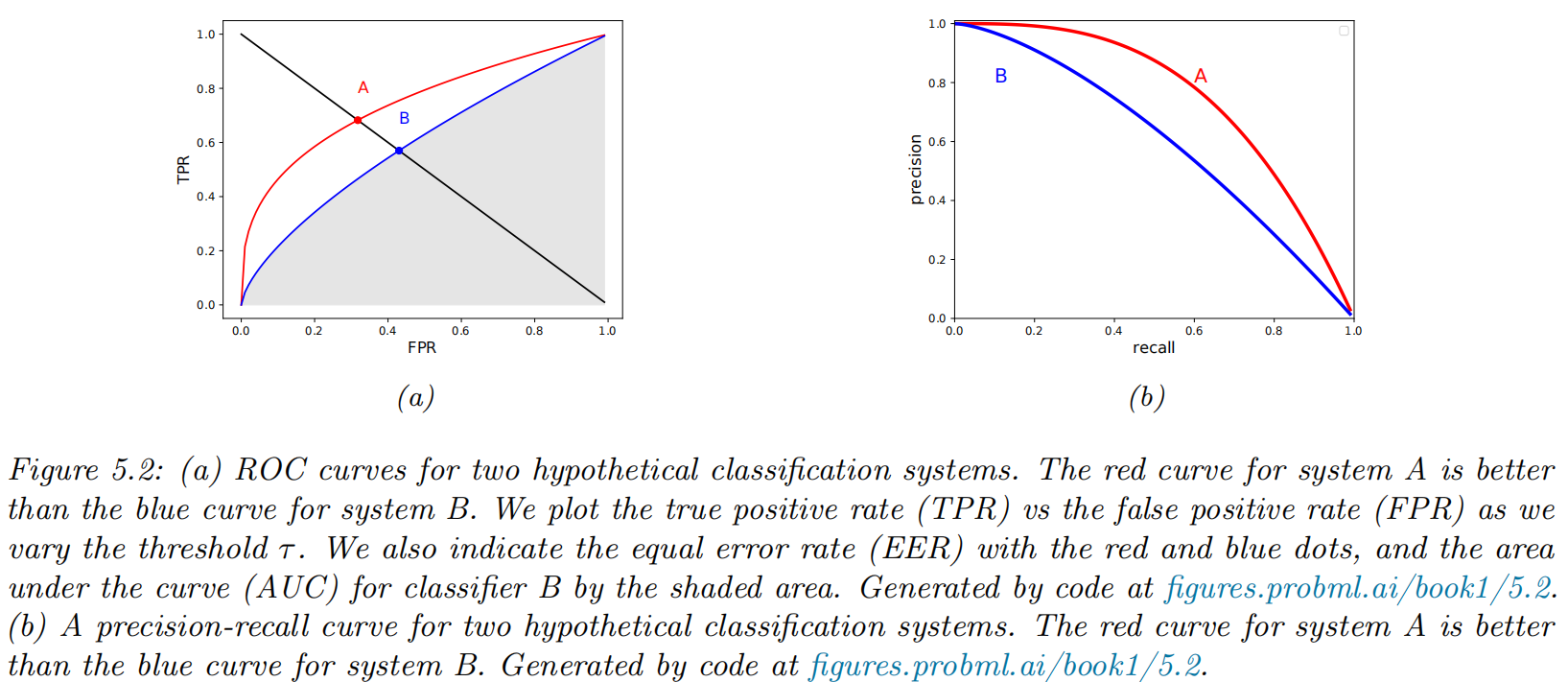
Summarizing ROC curves as a scalar
- Area Under the Curve (AUC)
- higher AUC scores are better
- the maximum is 1
- Equal Error Rate (EER) or cross-over rate
- defined as the value which satisfies FPR = FNR
- lower EER scores are better
- the minimum is 0
Precision-recall curves
Computing precision and recall
- the precision:
- the recall
- If is the predicted label, and is the true label, we can estimate precision and recall using
Summarizing PR curves as a scalar
- the precision at K score: quote the precision for a fixed recall level, such as the precision of the first K = 10 entities recalled
- the interpolated precision: compute the area under the PR curve
- the average precision: the average of the interpolated precision, which is equal to the area under the interpolated PR curve
- the mean average precision or mAP: the mean of the AP over a set of different PR curves
F-scores
- Definition
- A special case:
Regression problems
We assume the set of actions and states are both equal to the real
line, .
L2 loss
- the loss, also called squared error or quadratic loss
- the risk function
- the minimum mean squared error estimate or MMSE estimate
- The loss penalizes deviations from the truth quadratically, and thus is sensitive to outliers.
L1 loss
- the loss, also called squared error or quadratic loss
- the optimal estimate is the posterior median
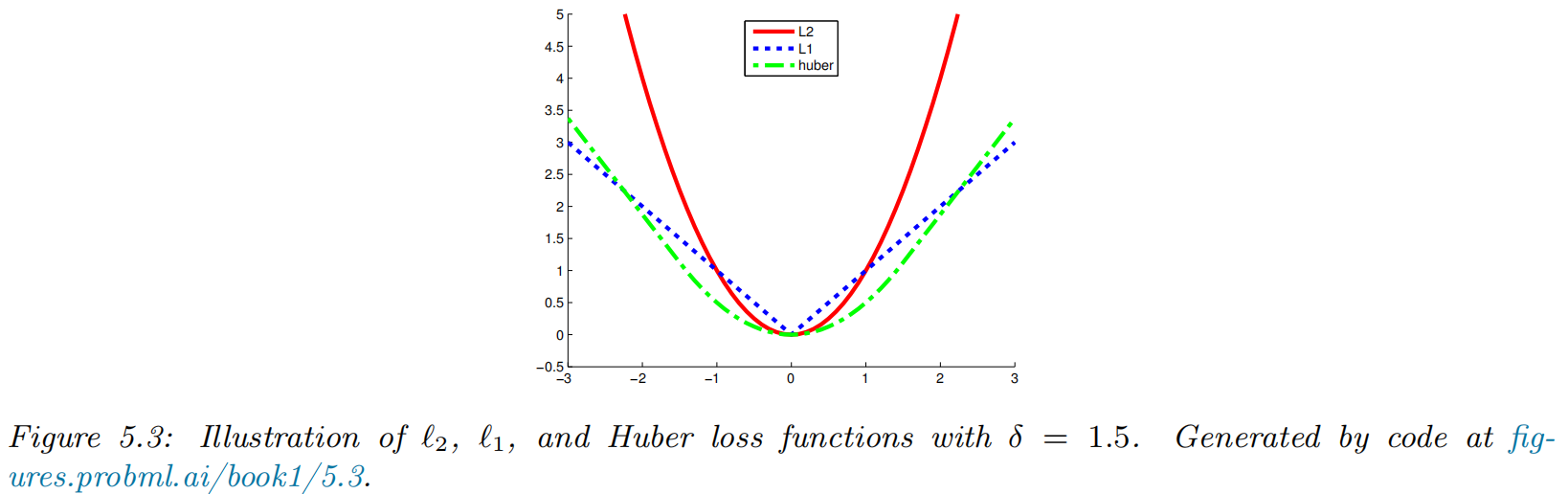
Huber loss
Let ,
Probabilistic prediction problems
We assume the true “state of nature” is a distribution, , the action is another distribution, , and we want to pick to minimize for a given .
KL, cross-entropy and log-loss
A common form of loss functions for comparing two distributions is the Kullback Leibler divergence, or KL divergence, which is defined as follows:
-
The KL is the extra number of bits we need to use to compress the data due to using the incorrect distribution .
-
minimize the cross-entropy
Proper scoring rules
- proper scoring rule: a loss function satisfies the follwoing
- Brier score:
Choosing the "right" model
Bayesian hypothesis testing
- two hypothesis / model
- null hypothesis:
- alternative hypothesis:
- 0-1 loss
- Bayes factor: the ratio of marginal likelihoods of the two models
| Bayes factor | Interpretation |
|---|---|
| Decisive evidence for | |
| Strong evidence for | |
| Moderate evidence for | |
| Weak evidence for | |
| Weak evidence for | |
| Moderate evidence for | |
| Strong evidence for | |
| Decisive evidence for |
Example: Testing if a coin is fair
- test if a coin is fair
- : faire, i.e.
- : unfair, i.e.
- marginal likelyhood under
- :
- with a Beta prior:
- :

Bayesian model selection
- Model Selection: pick a most apprppriate model from a set of more than 2 models
- posterior
- uniform prior
- marginal likelyhood
Example: polynomial regression

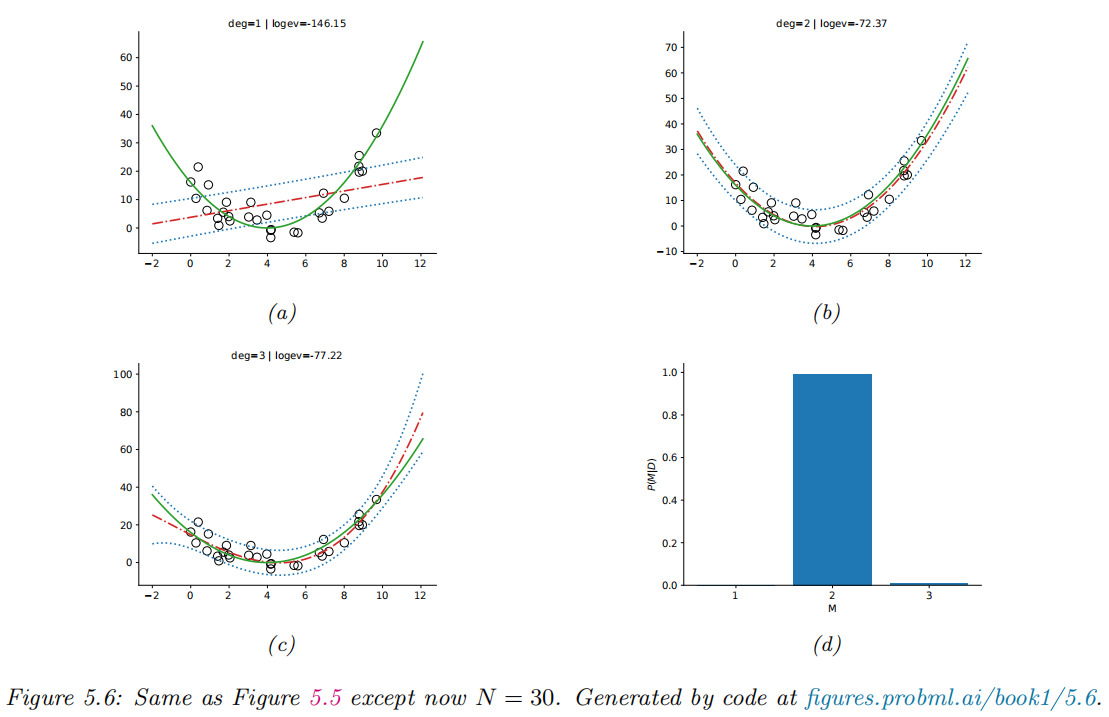
Occam's razor
-
Occam’s razor: the simpler the better (for the same marginal likelyhood)
-
Bayesian Occam’s razor effect: the marginal likelihood will prefer the simpler model.

Connection between cross validation and marginal likelihood
Marginal likelihood is closely related to the leave-one-out cross-validation (LOO-CV) estimate.
where
Suppose we use a plugin approximation to the above distribution to get
Then we get
Information criteria
- the marginal likelyhood can be difficult to compute
- the result can be quite sensitive to the choice of prior
The Bayesian information criterion (BIC)
- The Bayesian information criterion or BIC can be thought of as a simple approximation to the log marginal likelihood.
where H is the Hessian of the negative log joint evaluated at the MAP estimate .
- Assuming uniform prior, , we can drop the prior term, and replace the MAP estimate with the MLE,
- the BIC score
- the BIC loss
Akaike information criterion
- This penalizes complex models less heavily than BIC, since the regularization term is independent of .
- This estimator can be derived from a frequentist perspective.
Minimum description length (MDL)
Frequentist decision theory
Computing the risk of an estimator
We define the frequentist risk of an estimator π given an unknown state of nature to be the expected loss when applying that estimator to data sampled from the likelihood function :
Example: estimate a Gaussian mean
- assume the data is sampled from
- quandratic loss:
- risk function: MSE
- 5 different estimators for computing
- sample mean:
- sample median:
- a fixed value:
- : the posterior mean under a
- weak case:
- strong case:
- MSE:
- sample mean:
- sample median:
- fixed value:
- postior:
- sample mean:
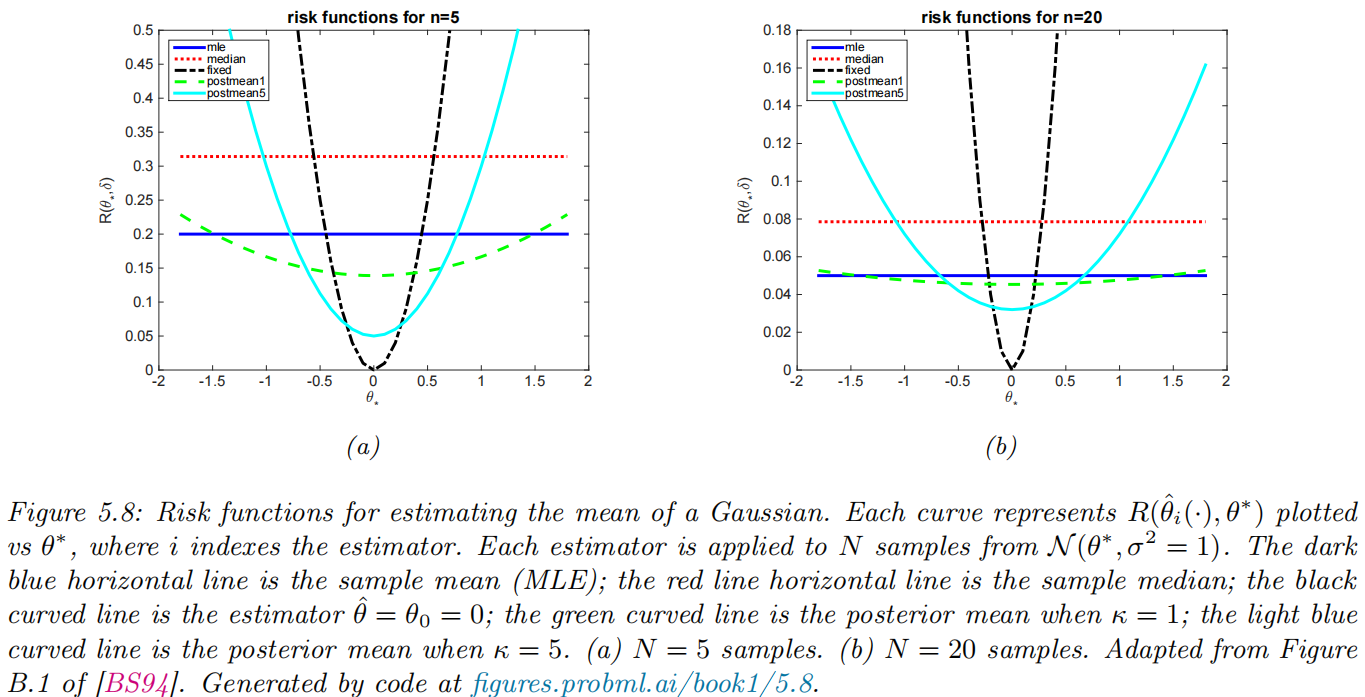
Bayes risk
-
Bayes risk (integrated risk):
-
Bayes estimator
Maximum risk
- Maximum risk
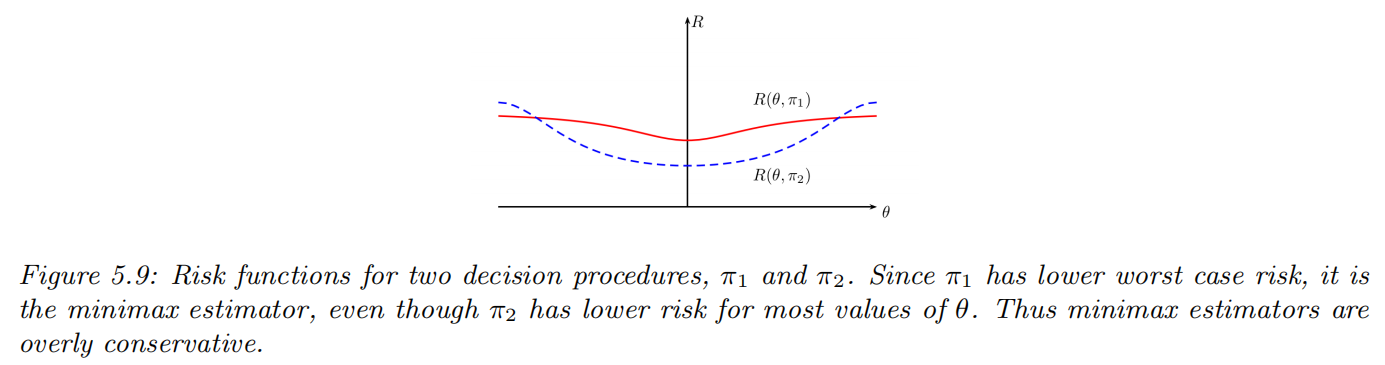
Empirical risk minimization
Empirical risk
- Population risk
-
Empirical risk
- Empirical distribution
- Empirical risk
- Empirical distribution
-
Empirical risk minimization (ERM)
Approximation error vs estimation error
-
Notations
- : function that achieves the minimal possible population risk
- : the best function in the hypothesis space
- : the prediction function that minimizes the empirical risk in the hypothesis space
-
Error decomposition: approximation error () vs. estimation error or generalization error ()
-
generalization gap
Regularized risk
- regularized empirical risk
- measures the complexity of the prediction function
- is known as a hyperparameter
- parametric function form
- log loss, negative log prior regularizer
Minimizing this is equivalent to MAP estimation.
Structural risk
-
how to minimize empirical risk?
-
It does not work (optimism of the training error)
-
structural risk minimization: If we knew the regularized population risk , instead of the regularized empirical risk , we could use it to pick a model of the right complexity (e.g., value of )
-
two methods to estimate the population risk for a given model (value of )
- cross-validation
- statistical learning theory
Cross-validation
- partition the dataset into two
- training set : to fit/train the model
- validation set or holdout set: to assess the risk
- the empirical risk on the dataset
- validation risk: use the unregularized empirical risk on the validation set as an estimate of the population risk
- K-folds cross validation (CV):
- split the training data into K folds
- for each fold , we train on all the folds but the k’th
- test on the k’th
- cross-validated risk
- optimal parameters
- optimal hyperparameters:
- optimal model parameters:
Information Theory
Entropy
The entropy of a probability distribution can be interpreted as a measure of uncertainty, or lack of predictability, associated with a random variable drawn from a given distribution. We can also use entropy to define the information content of a data source.
| Entropy of | Hard/Easy to predict | Information content of |
|---|---|---|
| high | hard | high |
| low | easy | low |
Entropy for discrete random variables
The entropy of a discrete random variable with distribution over states is defined by
- When we use log base 2, the units are called bits (short for binary digits).
- When we use log base , the units are called nats.
Cross entropy
The cross entropy between distribution and is defined by
The cross entropy is the expected number of bits needed to compress some data samples drawn from distribution using a code based on distribution . This can be minimized by setting , in which case the expected number of bits of the optimal code is — this is known as Shannon’s source coding theorem.
Joint entropy
The joint entropy of two random variables and is defined as
For example, consider choosing an integer from 1 to 8, . Let if is even, and if is prime:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |
| 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
The joint distribution is
so the joint entropy is given by
Consider the marginal entropys:
We observe that
In general, the above inequality is always valid. If X and Y are independent, then , so the bound is tight. This makes intuitive sense: when the parts are correlated in some way, it reduces the “degrees of freedom” of the system, and hence reduces the
overall entropy.
Another observation is that
this says combining variables together does not make the entropy go down: you cannot reduce uncertainty merely by adding more unknowns to the problem, you need to observe some data.
Conditional entropy
The conditional entropy of given is the uncertainty we have in after seeing , averaged over possible values for :
It is straight forward to verify that:
Perplexity
The perplexity of a discrete probability distribution is defined as
It is often interpreted as a measure of predictability. Suppose we have an empirical distribution based on data :
We can measure how well predicts by computing
Differential entropy for continuous random variables *
If is a continuous random variable with pdf , we define the differential entropy as
Differential entropy can be negative since pdf’s can be bigger than 1.
Example: Entropy of a Gaussian
The entropy of a d-dimensional Gaussian is
In the 1d case, this becomes
Linear Algebra
Matrix calculus
Derivatives
Gradients
- Patial derivative:
- Gradient:
- Gradient evaluated at point :
Directional derivative
The directional derivative measures how much the function changes along a direction in space. It is defined as follows
Note that the directional derivative along is the scalar product of the gradient g and the vector :
Total derivative
Suppose that some of the arguments to the function depend on each other. Concretely, suppose the function has the form . We define the total derivative of wrt t as follows:
If we multiply both sides by the differential , we get the total differential
This measures how much f changes when we change , both via the direct effect of on , but also indirectly, via the effects of t on and .
Jacobian
Consider a function that maps a vector to another vector, . The Jacobian matrix of this function is an matrix of partial derivatives:
Multiplying Jacobians and vectors
The Jacobian vector product or JVP is defined to be the operation that corresponds to right multiplying the Jacobian matrix by a vector :
So we can see that we can approximate this numerically using just 2 calls to .
The vector Jacobian product or *VJP is defined to be the operation that corresponds to left-multiplying the Jacobian matrix by a vector :
Jacobian of a composition
Let . By the chain rule of calculus, we have
Hessian
For a function f : Rn → R that is twice differentiable, we define the Hessian matrix as the (symmetric) matrix of second partial derivatives:
The Hessian is the Jacobian of the gradient.
Gradients of commonly used functions
